在人工智能算力网络领域,一个新的趋势正在悄然兴起——超节点。这一概念的提出,源于大模型参数的不断增长和模型架构的持续演变,使得传统的算力扩容方式已难以满足需求。Scale-up(纵向扩展)和Scale-out(横向扩展)作为算力系统扩容的两个关键维度,为我们理解这一趋势提供了重要视角。
以货轮运输为例,当运力需求增加时,Scale-up相当于建造更大的货轮,而Scale-out则是增加货轮的数量。在AI领域,Scale-up追求硬件的紧密耦合,以实现高性能计算;而Scale-out则追求弹性扩展,以支撑松散的任务,如数据并行。这两者在协议栈、硬件和容错机制上存在显著差异,导致通信效率各不相同。
以英伟达DGX系列为例,DGX A100通过Infiniband交换网络实现Scale-out,而DGX H100则通过NVSwitch实现256个H100 GPU的全互联,形成超节点,从而在通信性能上占据优势。这种超节点实际上是在单个或多个机柜层面进行的Scale-up,节点内主流通信方案采用铜连接与电气信号,跨机柜则考虑引入光通信。
英伟达在超节点领域的技术探索尤为引人注目。其推出的DGX GH200系统,将Grace CPU和Hopper GPU封装在同一块板卡上,形成“刀片服务器”,并通过内部线缆和光模块与专门设计的NVLink交换机连接。而随后的GB200 NVL72超节点产品,则借助第五代NVLink,实现了最大576个GPU的扩容,其中商用方案在机柜层面连接72个GPU,显著提升了Scale-up的带宽与寻址性能。
在拓扑结构上,GB200 NVL72中的72个B200 GPU通过单层的NVSwitch实现全互联,每个B200对超节点内其他71个GPU的通信带宽均达到1800GB/s,显著提升了应对通信峰值的能力。与此同时,Scale-out方案则依靠InfiniBand或以太网,通过高带宽网卡与交换机,带动光模块和交换机的放量。
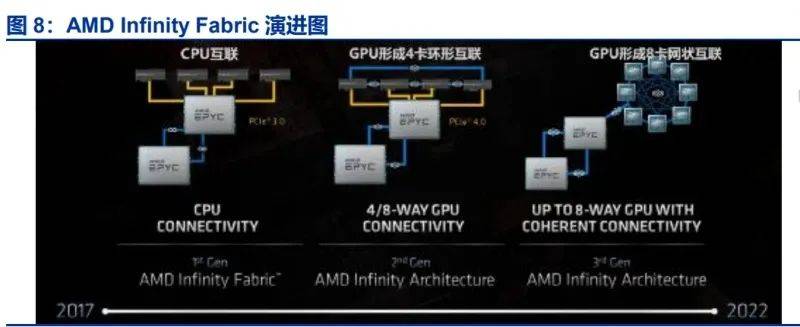
除了英伟达,AMD也在探索超节点的新路径。其Infinity Fabric互联总线技术,既用于芯片内部的不同模组,也用于外部互联。AMD计划在26H2推出搭载128个MI450X的超节点产品,通过实现以太网Scale-up,打造新的超节点互联方式。与NVL72不同,MI450X IF128通过IFoE(Infinity Fabric over Ethernet)连接,一定程度上打破了Scale-up和Scale-out的界限。
然而,超节点的发展并非一帆风顺。特斯拉的Dojo系统就是一个典型的例子。Dojo是特斯拉专为神经网络和自动驾驶汽车设计的AI训练超级计算机,其采用全定制的芯片和软件栈,与传统AI架构形成鲜明对比。然而,Dojo的封闭生态和2D Mesh拓扑结构却成为其发展的重要掣肘。由于硬件设计与传统GPU架构显著不同,Dojo在搭建软件栈时需要自上而下的完全重构,这增加了与主流AI框架对齐的成本。2D Mesh拓扑的弹性较弱,不利于全局通信,不符合主流大模型的趋势。
面对超节点的挑战,华为等厂商也在积极探索解决方案。华为认为,超节点的发展需要综合考虑硬件、软件和通信协议等多个方面。通过优化硬件设计、提升软件兼容性和改进通信协议,可以有效解决超节点在扩展性、性能和成本等方面的问题。华为的技术探索为超节点的发展提供了新的思路和方向。