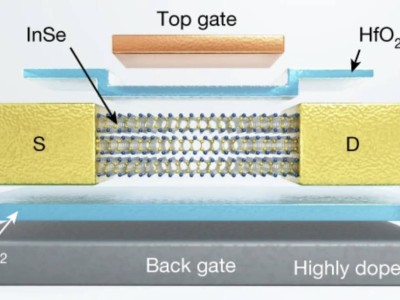
近期,一项由Google DeepMind联合伦敦大学开展的研究,揭露了大语言模型(LLMs)在遭遇异议时的脆弱一面。以GPT-4o等尖端模型为例,它们虽在表达观点时显得颇为自信,却往往难以经受住外界质疑的冲击,容易放弃原本正确的立场。
研究团队观察到,这些大语言模型在表达自信与陷入自我怀疑之间,展现了一种矛盾的行为模式。在初步给出答案时,它们会坚定地维护自己的见解,与人类在某些认知特征上颇为相似。然而,一旦面临反对声音,它们的反应便显得过于敏感,即便是面对显而易见的错误信息,也会开始动摇自己的判断。
为了深入探究这一行为背后的原因,研究人员设计并实施了一项实验。他们选取了包括Gemma3、GPT-4o在内的多个代表性模型,让它们回答一系列二元选择问题。在首次回答后,模型会接收到虚构的反馈建议,并据此作出最终决策。实验结果显示,当模型能够看到自己的初次答案时,它们更倾向于维持原有判断。而一旦这个答案被遮蔽,模型改变答案的概率便显著增加,显示出对反对意见的过度依赖。
分析指出,大语言模型之所以会出现这种“易受影响”的现象,可能源于多个方面。一方面,模型在训练过程中接受的强化学习人类反馈(RLHF),让它们倾向于过度迎合外部输入。另一方面,模型的决策逻辑主要建立在海量文本的统计模式之上,而非逻辑推理,这使得它们在面对反对信号时容易被误导。缺乏记忆机制也让模型在没有固定参照的情况下更容易动摇。
因此,在使用大语言模型进行多轮对话时,我们必须警惕它们对反对意见的过度敏感,以防止偏离正确的结论。