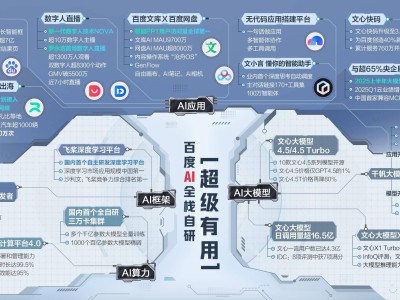
在人工智能领域,大模型的应用正逐步从预训练阶段向后训练阶段转移,这一趋势在xAI最新发布的Grok 4模型中得到了显著体现。这款被埃隆·马斯克誉为“宇宙最强模型”的大模型,通过20万块GPU组成的Colossus超级计算机集群训练而成,拥有25.6万tokens的上下文窗口,主打多模态功能,支持复杂交互,推理速度更快,用户界面也更为优化。
Grok 4在“人类最后的考试”中表现突出,准确率达到了38.6%,超越了谷歌Gemini 2.5 Pro和OpenAI o3等模型。多智能体版本Grok 4 Heavy更是达到了44.4%,辅以工具辅助后,准确率提升至50.7%。在与其他模型的基准测试中,Grok 4同样表现出色,位居前列。
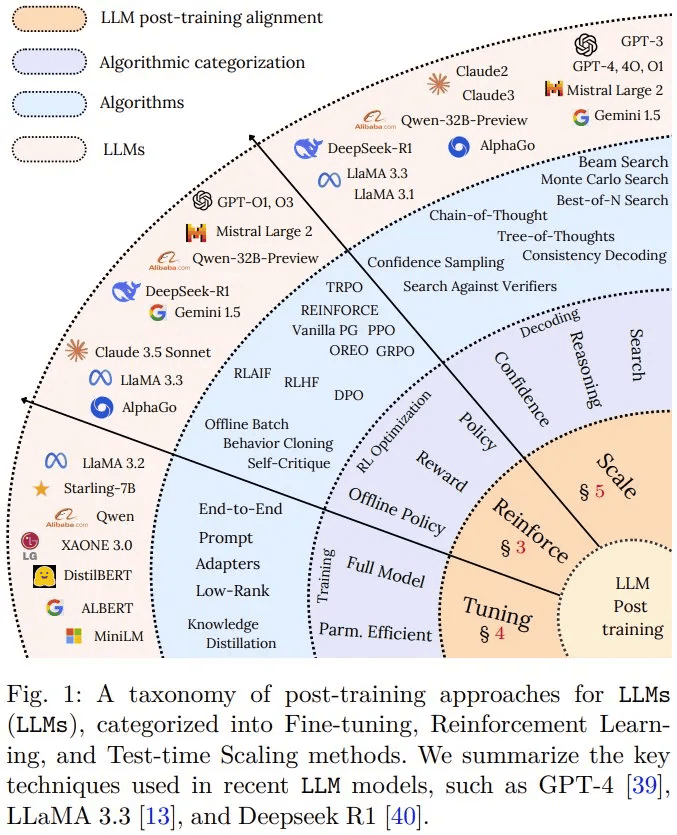
马斯克在发布会上表示,Grok 4在所有学科中均达到了研究生水平,甚至超越了许多PhD的能力。这一成就的背后,后训练技术发挥了关键作用。随着基础大模型在通用能力上的边际效益递减,AI技术范式正逐渐从注重预训练转向注重后训练,后训练成为决定模型最终价值的关键环节。
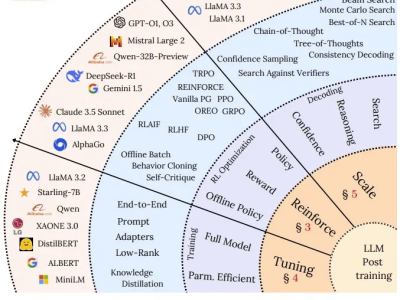
后训练阶段通常包括多轮微调和对齐,旨在优化模型行为,使其与人类意图对齐,减少偏见和不准确度。通过微调、强化学习、思维链、低秩适应等技术,后训练能够提升模型的计算效率和准确性,实现知识精炼、能力对齐和推理增强。
产业应用方面,后训练技术同样发挥着重要作用。在出行、住房、教育等领域,通用大模型在面临专业领域问题时常常出现知识断层和幻觉现象。通过增量预训练、监督微调、知识图谱等技术手段,企业正努力提升大模型在行业应用中的表现。例如,某汽车门户网站通过“增量预训练+SFT+知识图谱”的方法,使大模型在车型信息问答和导购方面的准确率显著提升。
为了进一步提升大模型的适用性和准确性,业界还在探索新的后训练方法。例如,采用MoE模型作为基础模型,通过动态路由算法优化计算效率;使用FP8精度数据,在几乎无损精度的情况下大幅提升训练和推理效率。这些新技术不仅提升了模型的性能,也降低了训练成本。
夸克高考大模型是后训练技术应用的又一成功案例。该模型以通义千问系列的MoE模型为基座,通过增量预训练、监督微调、可验证奖励的奖励强化学习(RLVR)和人类反馈强化学习(RLHF)等步骤进行后训练。经过后训练的模型能够基于模拟的考生档案生成志愿填报方案,并通过专家反馈进行策略评分和优化。截至7月8日,夸克高考服务了全国超4000万考生及家长,累计生成了超过1200万份AI志愿报告。
在后训练过程中,数据、评估、奖励机制、可扩展性和基础设施等五大关键要素共同决定了模型的最终性能。为了应对这些挑战,企业需要稳定、高效、全能的平台支持。阿里云通过其全栈AI能力,为企业提供从算力到平台的“后训练”一体化支撑,包括全球部署的基础设施、领先的模型基座、高效的训练框架以及坚实的数据底座和完善的部署闭环。
随着大模型的发展从“规模的军备竞赛”转向“深度适配业务场景的价值创造”,越来越多的企业认识到“云+AI”融合的重要性。阿里云的全栈AI能力正在将后训练从复杂的“工程问题”转变为清晰的“业务问题”,帮助企业将宝贵精力聚焦于核心业务创新,抓住AI时代的机遇。