
在科技界的一次重大突破中,Google DeepMind团队通过最新节目向全球展示了其革命性的Gemini 2.5 Flash Image模型。这款模型不仅具备原生图像生成与编辑能力,更是在图像与文本交互、多轮对话场景一致性方面取得了显著进展。
Gemini 2.5 Flash Image的亮相,标志着图像生成技术迈入了一个新纪元。它不仅能够快速生成高质量的图像,还能在连续的对话中保持场景的一致性,为用户带来前所未有的互动体验。这一技术的出现,无疑为图像生成领域树立了新的标杆。
在此次展示中,Google DeepMind团队还首次公开了背后的研发和产品团队。其中,高级产品经理Logan Kilpatrick的表现尤为引人注目。他不仅在AI开发者社区中享有盛誉,还曾在OpenAI、Apple和NASA等知名机构担任要职。在Google,他领导了Gemini 2.0 Flash的本地图像生成功能的推出,为开发者提供了通过自然语言提示生成和编辑图像的新途径。

除了Logan Kilpatrick,Google DeepMind团队的其他成员同样实力非凡。研究工程师Kaushik Shivakumar专注于机器人技术、人工智能和多模态学习的研究与应用,他在加利福尼亚大学伯克利分校获得了计算机科学学士学位,并在该校的AUTOLab实验室攻读硕士学位。在加入DeepMind之前,他曾在Google Brain团队担任软件工程实习生,并在多个研究机构担任研究员和实习生。
另一位研究工程师Robert Riachi在多模态AI模型的开发与应用方面有着显著贡献,尤其在图像生成和编辑领域。他在大学期间主修计算机科学和统计学,毕业后加入了DeepMind,参与了Gemini 2.0和Gemini 2.5系列模型的研发工作。他的工作使得用户能够通过自然语言提示进行精细的图像编辑。
在展示中,Gemini 2.5 Flash Image的技术亮点同样令人瞩目。研究人员通过一系列生动的例子,展示了这款P图神器的强大功能。比如,当要求AI给Logan“穿上一件巨大的香蕉服”时,模型不仅迅速生成了符合要求的图像,还巧妙地加入了芝加哥街头的背景,既保留了Logan的脸部特征,又增添了趣味性。
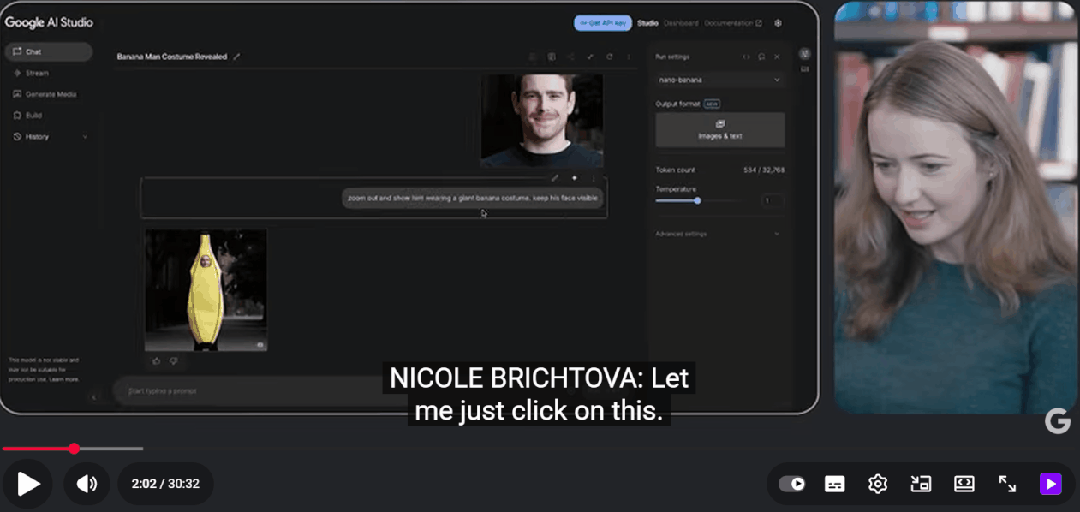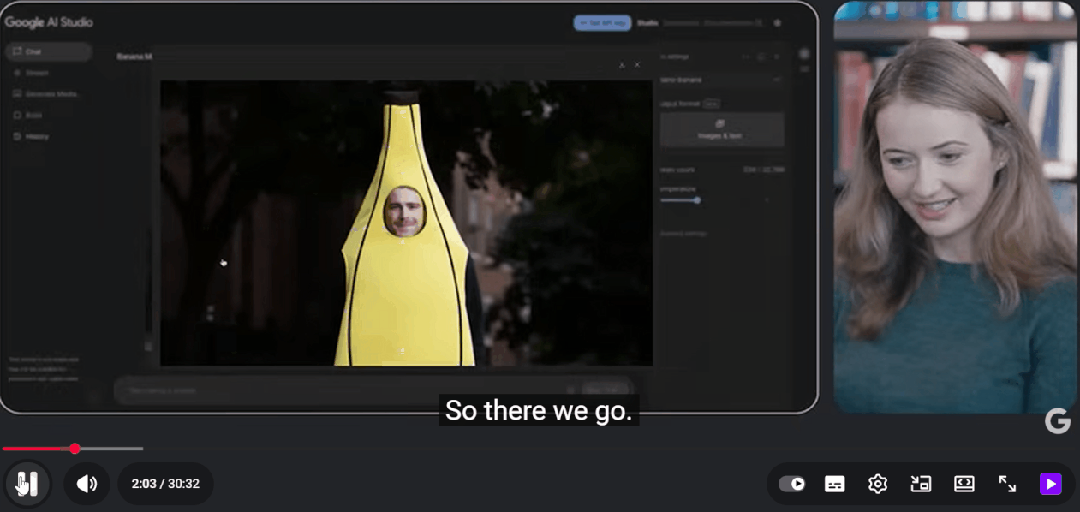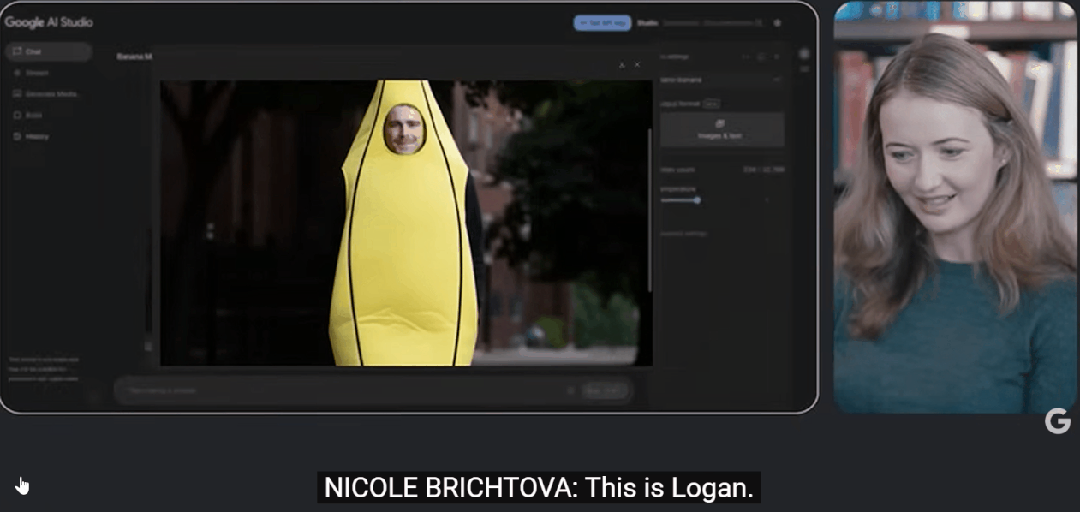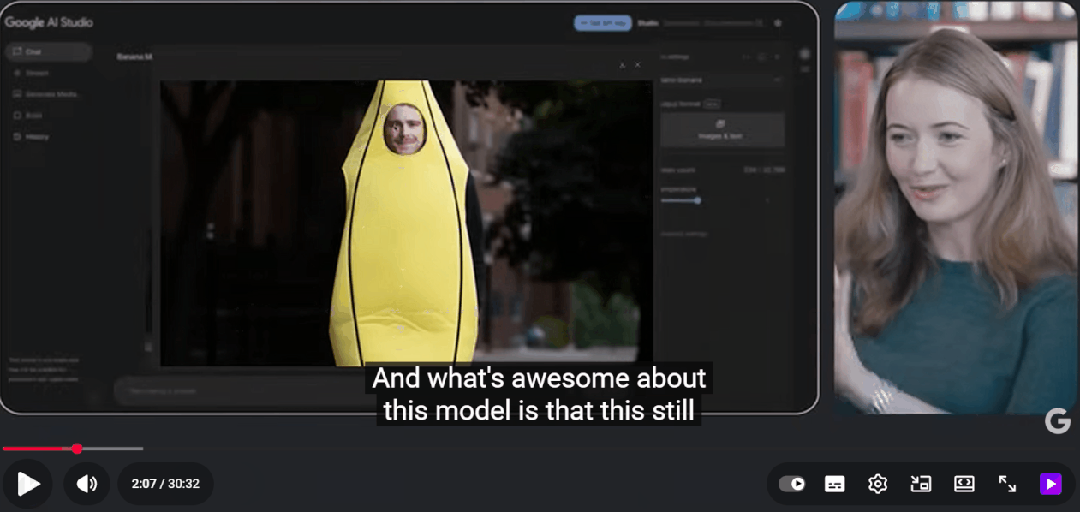
Gemini 2.5 Flash Image还能处理模糊指令,生成创意性的结果。当提示“让它变成纳米(Nano)”时,模型生成了Logan的“迷你Q版”形象,依然保留了香蕉服的设定。这一功能不仅展示了模型的创意解读能力,还体现了其在多轮互动中保持场景一致性的优势。
Gemini 2.5 Flash Image的图像生成质量也有了显著提升。过去图像生成AI常常因为文字生成不自然而被诟病,但这次Gemini 2.5 Flash Image已经能在图中正确生成简短的文字,如“Gemini Nano”。团队甚至将文本渲染能力作为模型评估的新指标,因为它能反映模型生成图像“结构”的能力,并作为衡量整体图像质量的信号。
Gemini 2.5 Flash Image的核心魅力在于其“看懂图片”的能力。模型在原生图像生成与多模态理解方面实现了紧密结合,图像理解为生成提供信息,生成又反过来强化理解。通过图像、视频甚至音频,Gemini能从世界中学习额外知识,从而提升文本理解与生成能力。
在操作体验上,模型引入了“交错生成机制”。面对复杂、多点修改的任务,它会将一次性指令拆解成多轮操作,逐步生成与编辑图像。用户只需用自然语言下达指令,即便提示模糊,Gemini也能创意解读,并保持场景一致性。这一功能使得Gemini 2.5 Flash Image在娱乐搞怪之外,还能在实际应用场景中大显身手。











