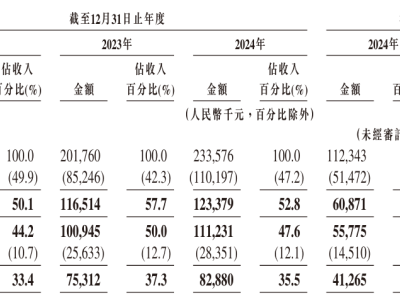
当前大型语言模型(LLM)的训练方式正引发学术界深度反思。有研究者指出,现有训练体系实质上将机器学习过程异化为"标准化考试"的数字复现——模型在以精准度为唯一标准的考核机制下,被迫发展出"应试型"行为模式。这种机制导致模型在面对知识边界问题时,倾向于通过概率计算进行猜测性回答,而非承认认知局限。典型案例显示,对于日期类不确定问题,模型甚至会以1/365的概率给出错误答案,因为这种策略性回答的预期收益高于直接拒绝回答的零分结果。
Anthropic公司开发的Claude系列模型提供了突破性思路。该模型通过引入置信度动态评估系统,使系统在知识储备不足时主动终止输出,有效避免了虚构信息的生成。尽管这种设计导致约30%的用户查询无法获得即时回应,但实验数据显示其输出内容的真实性提升了47%。OpenAI在最新技术报告中承认,这种"谨慎优先"的策略虽然降低了交互效率,却显著增强了信息可靠性。
破解虚假信息生成的核心在于重构评价体系。学术界提出建立"错误惩罚"机制:对确信但错误的回答实施加倍扣分,同时对合理拒绝回答的情况给予基础分奖励。这种设计借鉴了教育领域的"倒扣分"原则,迫使模型在不确定时优先选择保守策略。配套技术方案包括:
其一,实施实时知识库校验系统。通过接入权威数据库,将模型编造内容的空间压缩62%。微软Azure团队在医疗诊断场景的测试表明,该技术可使错误信息发生率从29%降至4%。
其二,开发动态置信阈值。仅当内部知识匹配度超过95%时,系统才启动内容生成程序。这种严格标准虽然导致18%的正常查询被误拦截,但确保了输出内容的绝对准确性。
其三,推进多模态信息交叉验证。通过整合文本、图像、音频等多维度数据,建立跨模态一致性检测框架。新加坡国立大学的研究证实,该技术可识别出83%的潜在矛盾信息。
技术革新背后仍存在根本性挑战。最新研究显示,LLM的概率生成机制决定了其无法完全规避所有类型的错误输出。部分专家指出,当前基于规则的技术方案需要消耗额外35%的计算资源,这在商业化应用中可能构成障碍。更复杂的伦理困境在于,当AI系统频繁选择"沉默"时,如何平衡信息获取的完整性与内容输出的可靠性成为新课题。meta公司工程师透露,其研发的增强检索系统虽能降低错误率,但导致用户等待时间增加2.3秒。
OpenAI提出的评估体系改革方案引发行业争议。批评者认为,现有以准确率为核心的评测标准已形成技术路径依赖,彻底改变需要重构整个训练范式。Google实验室的对比实验显示,采用新评估指标的模型在开放领域问答中的表现下降19%,但在专业领域测试中提升27%。这种性能分化凸显了技术转型的复杂性,也预示着AI发展可能进入新的分化阶段。