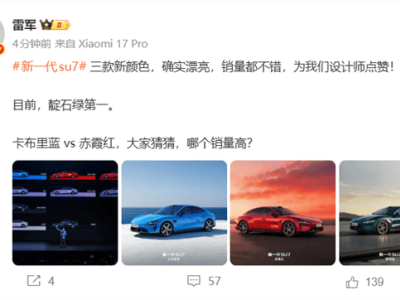
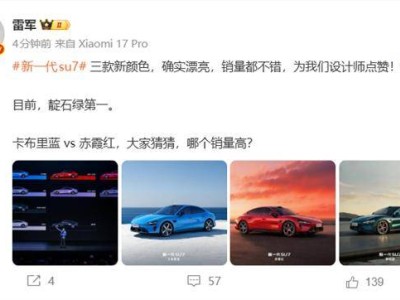
当行业还在为模型参数规模激烈竞争时,AI智能体的核心战场已悄然转向效率与成本。浪潮信息在2025人工智能计算大会上推出的两款AI服务器,以突破性技术重新定义了行业标准:元脑SD200将智能体交互延迟压缩至8.9毫秒,元脑HC1000则把大模型推理成本降至1元/百万token。
英伟达创始人黄仁勋在GTC大会上指出,当AI具备环境感知与逻辑推理能力时,真正的智能体时代即告来临。这种数字世界的"智能机器人"通过"理解-思考-行动"的闭环,正在重构人机交互范式。Gartner预测,到2028年将有15%的日常决策由AI智能体参与完成,而Georgian报告显示91%的企业技术主管已将智能体部署纳入战略规划。
行业实践暴露出关键瓶颈。某海外团队基于Azure OpenAI服务开发的智能体,在三个月内响应时间从2秒恶化至10秒以上。测试发现,相同提示词下OpenAI原生API仅需1-2秒,而Azure平台却要5-10秒。这种五倍的性能差异,在需要毫秒级响应的金融交易、工业控制等场景中可能造成灾难性后果。
成本压力同样严峻。某AI编程平台数据显示,开发者月均token消耗量较去年激增50倍,达到1000万-5亿token规模。企业部署单个智能体的年均成本高达1000-5000美元,而未来五年token需求预计增长百万倍。这种指数级增长的压力,迫使行业重新审视技术架构。
浪潮信息的解决方案直指要害。元脑SD200超节点服务器采用首创的3D Mesh系统架构,实现64路AI芯片纵向扩展,构建出4TB显存和6TB内存的超大KV Cache空间。其跨主机统一物理地址技术,将显存扩展能力提升8倍,配合百纳秒级基础通信延迟和微秒级链路重传机制,最终达成0.69微秒的行业最低通信延迟。
在DeepSeek R1大模型测试中,SD200创造了8.9毫秒的国内最快推理纪录。这得益于其分布式预防式流控机制和单节点64卡全局最优路由设计,使系统通信耗时控制在10%以内。以6710亿参数的DeepSeek R1为例,从16卡扩展到64卡时实现了16.3倍的超线性性能提升,确保高并发场景下的稳定低延迟。
成本优化方面,元脑HC1000超扩展服务器通过全对称DirectCom架构实现革命性突破。该架构采用16卡计算模组设计,单卡成本降低60%以上,系统均摊成本下降50%。其计算通信1:1均衡配比和全局无阻塞通信设计,使推理性能提升1.75倍。在支持52万卡超大规模扩展的同时,通过自适应路由和智能拥塞控制算法,将KV Cache传输影响降低5-10倍。
技术演进呈现明确趋势。全球顶尖模型如o3、Gemini 2.5、Grok 4等持续刷新性能纪录,谷歌Gemini 3.0和OpenAI Sora 2预计十月发布。国内DeepSeek R1/V3.1、Qwen家族等开源模型已形成月更、周更的快速迭代体系。模型能力正从文本处理向多模态交互演进,逐步构建起AI时代的底层操作系统。
行业共识逐渐形成:智能体产业化需要能力、速度、成本的三维平衡。在欺诈防控等极端场景中,系统需要10毫秒内的响应能力,而当前主流模型30毫秒以上的延迟显然无法满足需求。浪潮信息的创新实践表明,通过专用计算架构实现软硬件深度协同,是突破算力瓶颈的关键路径。