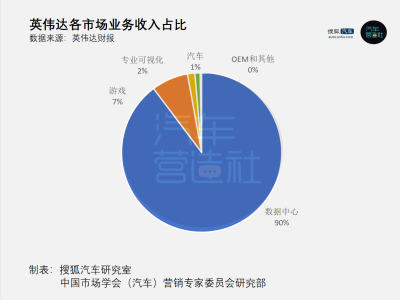
科技领域近日迎来一项引人瞩目的进展——谷歌公司研发的新一代人工智能图像生成模型Nano Banana 2,其早期预览版本在正式发布前意外现身网络。该模型在Media.ai平台短暂上线后虽被紧急下架,但相关技术演示内容已在社交平台引发广泛讨论,其展现的图像处理能力被业内视为重要突破。
据技术分析,该模型的核心优势体现在两大技术维度。在物理逻辑模拟方面,其通过"图生图"技术实现了对动态场景的精准还原。例如在演示案例中,模型能根据输入的静态图像,自动生成小球运动轨迹的完整动画序列,这种涉及重力、惯性等物理参数的计算能力,显著超越了现有同类产品的表现水平。
文本生成领域同样取得关键进展。测试数据显示,模型可基于自然语言指令,在白板、纸张等载体上生成排版规整的文本内容。与传统模型生成的模糊文字不同,新系统能精确控制字体样式、字号大小及字符间距,甚至支持多语言混合排版,为教育、设计等行业提供了高效的内容生成工具。
技术突破的背后,是模型对世界知识的深度理解能力。研发团队透露,通过引入多模态学习框架,系统不仅掌握图像像素间的关联规则,更能理解物体间的物理关系、场景语义等复杂信息。这种认知升级使模型在执行"让悬浮的杯子自然下落"等指令时,能自动生成符合物理规律的图像序列,而非简单的视觉拼接。
行业观察者指出,该技术的实用价值已超越学术研究范畴。在媒体内容生产领域,编辑人员可借助模型快速完成图片修复、色彩校正等基础工作;广告行业则能通过API接口实现营销素材的批量生成,将单张海报的制作周期从数小时压缩至分钟级。某创意工作室负责人表示:"这种自动化工具将彻底改变视觉内容生产的工作流程,设计师可以更专注于创意构思而非重复劳动。"
尽管目前公开的仅为预览版本,但技术社区已展开密集测试。开发者在GitHub平台分享的测试报告显示,模型在处理低分辨率图像时,能通过多尺度特征融合技术实现4倍清晰度提升,且在人物面部特征还原等细节处理上表现优异。不过也有专家提醒,当前版本在复杂场景的光影模拟方面仍存在改进空间,完整版发布时可能引入新的神经网络架构进行优化。