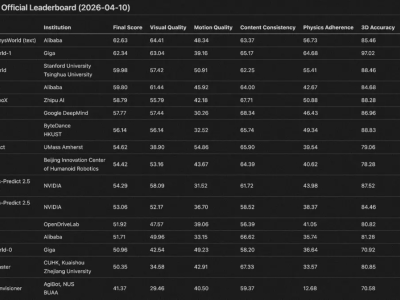
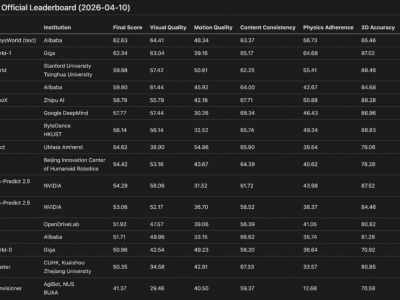
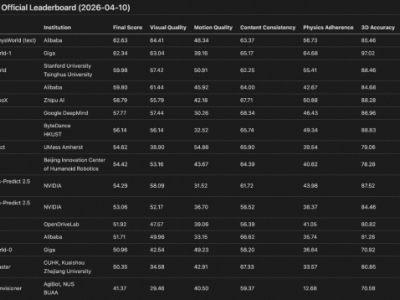
在NeurIPS 2025会议上,谷歌一口气发布了两项突破性研究,针对大模型架构提出全新解决方案。通过引入“测试时训练”机制,新架构成功将上下文处理窗口扩展至200万token,同时保持高效计算能力。这项成果被业界视为对Transformer架构的重大升级,尤其在处理超长序列任务时展现出显著优势。
研究团队指出,传统Transformer架构的自注意力机制存在根本性缺陷:当序列长度增加时,计算复杂度呈平方级增长(O(N²))。尽管学界已尝试线性循环网络(RNNs)和状态空间模型(SSMs)等替代方案,但这些方法在信息压缩过程中往往丢失关键上下文。谷歌此次提出的Titans架构与MIRAS理论框架,通过动态记忆机制实现了速度与性能的平衡。
Titans架构的核心创新在于引入神经长期记忆模块。与传统RNN固定大小的记忆单元不同,该模块采用多层感知机(MLP)结构,并在推理阶段持续更新权重。其MAC变体通过将长期记忆作为额外上下文输入注意力机制,在不改变基础计算方式的前提下,显著提升了模型对海量信息的概括能力。实验数据显示,该架构在“大海捞针”任务中保持高准确率的同时,成功将上下文窗口扩展至200万token。
记忆模块的更新策略借鉴了人类认知心理学中的“意外原则”。研究人员设计了“惊喜指标”来量化新输入与当前记忆的差异程度:当输入内容符合预期(如模型预测会出现动物词汇时出现“猫”)时,系统仅作短期存储;而当出现异常输入(如财务报告中突然出现香蕉皮图片)时,系统会优先将其纳入长期记忆。这种选择性更新机制使模型在保持高效的同时,精准捕捉关键信息。
作为理论支撑的MIRAS框架,则提供了序列建模的统一设计范式。该框架将任意序列模型解构为四个关键组件:内存架构、注意力偏差、保留门控和记忆算法。通过引入非欧几里得目标函数,MIRAS允许使用更复杂的数学优化机制。基于该框架开发的YAAD、MONETA和MEMORA三个无注意力模型,在实验中展现出超越Mamba 2等线性模型及同等规模Transformer的性能优势。
性能对比实验显示,新架构在处理极长上下文时表现尤为突出。在参数规模显著小于GPT-4等主流模型的情况下,其综合性能仍保持领先。研究人员特别强调,这种优势不仅体现在基准测试中,更在实际应用场景(如法律文书分析、科研文献综述)中得到验证。谷歌团队认为,这种混合架构为下一代大模型开发提供了全新思路。
在会议现场,谷歌首席科学家Jeff Dean回应了关于Transformer技术公开的争议。当被问及是否后悔将这项改变AI格局的技术开源时,他明确表示:“Transformer对全球技术发展产生了深远影响,这种开放共享的决策符合科技进步的本质。”这一表态引发与会者热烈讨论,多数专家认为,谷歌通过持续创新证明,技术领导力不在于固守既有成果,而在于不断突破自我边界。