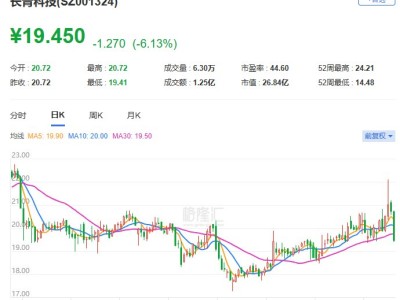
摩尔线程近日正式推出其全新GPU架构“花港”,该架构搭载了新一代指令集,在性能与能效方面实现了显著突破。据技术披露,新架构的算力密度较前代提升50%,同时能效比优化至原有水平的10倍,为大规模计算任务提供了更高效的硬件支持。
在技术特性上,“花港”架构集成了全精度端到端加速技术,可覆盖从低精度推理到高精度训练的完整计算需求。其集群扩展能力尤为突出,单架构支持超过10万张GPU的智算集群部署,为人工智能大模型训练、科学计算等场景提供了强大的底层算力支撑。
渲染与图形处理方面,该架构首次搭载第一代AI生成式渲染引擎,通过神经网络与图形管线的深度融合,实现了实时渲染效率与画面质量的双重提升。同时,第二代光线追踪硬件加速模块的引入,使光追计算效率较初代产品提升3倍以上,在复杂场景的光影模拟中表现更为出色。
行业分析指出,此次架构升级标志着国产GPU在高性能计算领域的技术跃迁。通过指令集重构与硬件单元优化,摩尔线程在保持架构兼容性的同时,针对性地解决了大规模并行计算中的功耗与延迟问题,为国产AI芯片在数据中心、智慧城市等领域的落地应用开辟了新路径。