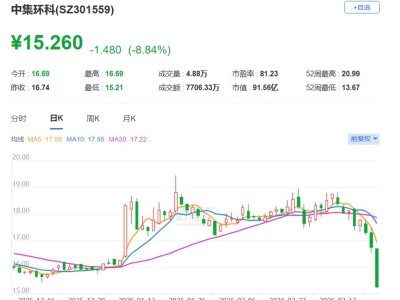
2025年,人工智能领域正经历着前所未有的变革。当各类AI应用如雨后春笋般涌现,从文案创作到情感陪伴,从供应链重塑到智慧医疗,技术的甜美果实似乎已触手可及。然而,在这片繁荣景象背后,上海的一批AI企业却选择了一条看似“逆流而上”的道路——持续深耕基础大模型研究。
回顾2023年,中国AI行业曾上演过一场激烈的“百模大战”。据统计,当时全国拥有10亿参数以上的大模型近80个,100亿参数级的大模型更是超过10个。然而,两年后的今天,这场狂欢已逐渐平息,仍在坚持基础大模型研究的企业已不足10家,其中商汤科技、稀宇科技、阶跃星辰等上海企业成为中坚力量。
为何在应用层创新层出不穷的当下,这些企业仍执着于基础研究?答案或许藏在谷歌的最新成果中。2025年11月,谷歌推出的新一代AI模型Gemini 3在LMArena排行榜上以1501分登顶,其数学能力测试得分率高达23.4%,远超竞争对手。这一成就被视为谷歌在AI领域的“绝地反击”,也印证了基础研究的重要性。谷歌选择坚持“理解生成一体化”路线,而非盲目追随行业潮流,最终凭借耐力实现了技术突破。
这种坚持在国内同样得到呼应。复旦大学计算机科学技术学院教授邱锡鹏曾指出,国内“百模大战”期间,大模型同质化问题严重,基础研究反而被忽视。以自然语言处理为例,2015年前该领域研究方向多样,学者间交流频繁,而当所有人都涌向语言模型赛道时,其他可能性被扼杀。这种现象凸显了基础研究在技术创新中的稀缺价值。
阶跃星辰副总裁李璟的观点代表了上海企业的共识:“基础大模型的能力决定了应用的上限。”这家成立不到3年的企业已发布22款基座模型,其最新推出的Step 3模型在视觉感知和复杂推理方面表现突出。李璟强调,当前大模型技术尚未收敛,过早转向应用开发可能面临技术迭代风险,一旦底层架构发生根本性变革,前期投入可能付诸东流。
商汤科技的战略调整提供了另一个典型案例。2024年底,这家成立十年的企业启动业务重组,推出“1+X”战略:将智能驾驶、家庭机器人、智慧医疗等应用业务整合为“X创新业务”,自身则聚焦生成式AI与视觉AI双引擎。这一调整并非技术路线的试探,而是对核心能力的再聚焦。2025年,商汤推出的“开悟”世界模型3.0在真实世界建模能力上表现优异,其生成的视频具备强时空一致性,甚至能与斯坦福大学World Labs的Marble模型展开竞争。
在应用层取得成功的企业同样没有放弃基础研究。稀宇科技(Minimax)的产品覆盖200多个国家和地区,个人用户超2亿,月活用户达2700万。然而,这家企业在2024年10月仍推出了文本大模型M2、视频模型海螺2.3等“全家桶”技术。其中,M2模型以10B激活参数在全球权威测评中冲入前五,开源排名第一,其综合成本仅为竞争对手Claude 4.5的8%,推理速度却是后者的近两倍。这种“高智能、低成本”的模式正在改写AI领域的竞争规则。
学术界对技术路线的讨论也日益活跃。复旦大学计算与智能创新学院教授张军平提醒,当前AI研究可能偏离了正确方向——人类智能的进化应遵循“感知先行、认知随后”的规律。与此同时,仍有学者坚持从“AI符号主义”路线中寻找突破,这种多元声音的复苏,为技术创新提供了更多可能性。
在创新成果触手可及的时代,颠覆性突破往往诞生于冷门领域。上海AI企业的选择,正是对这一规律的回应。当技术尚未收敛,一切皆有可能,而基础研究正是捕捉这种可能性的关键。