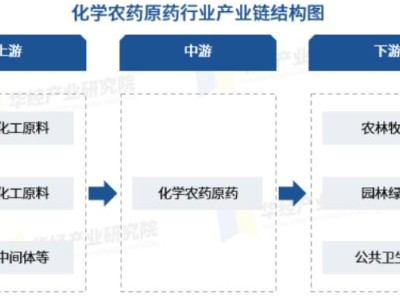
在自动化软件测试领域,一项突破性研究为开发者带来了效率革命。由西伯利亚神经网络公司牵头,联合T技术公司与新西伯利亚国立大学的研究团队,开发出名为RM-RF的智能评估模型,其核心创新在于颠覆了传统"运行才能验证"的测试评估模式。该模型通过直接分析代码文本,即可预测测试用例的质量指标,这项成果已发表于arXiv预印本平台(编号arXiv:2601.13097v1)。
传统测试评估流程犹如进行全面体检,需要经历编译代码、运行测试、计算覆盖率等复杂步骤。在大型项目中,完整评估周期可能长达数日,且消耗大量计算资源。研究团队将RM-RF模型比作资深医疗专家,仅通过"病历审查"就能判断健康状况——该模型通过解析源代码、现有测试用例和新增测试代码,即可预测测试能否正常运行、覆盖率提升幅度及突变检测有效性三大核心指标。
模型训练过程堪称构建"数字食谱库"。研究团队收集了22,285个多语言样本,涵盖Java、Python和Go三种主流编程语言。这个数据集不仅包含人工编写的测试代码,还特意混入AI生成和错误示例,确保模型能识别各类测试场景。通过对比零样本学习、完整参数微调及参数高效微调三种训练策略,研究人员发现70亿参数模型经完整微调后效果最佳,在三个评估维度上取得0.69的平均F1分数。
严格的评估体系确保了模型可靠性。研究团队采用项目级数据隔离策略,训练集与验证集完全来自不同开源项目。更特别构建了包含最新AI生成测试代码的测试集,这些代码均在模型训练完成后产生,有效避免数据泄露风险。实验数据显示,RM-RF在Java语言的突变检测中表现尤为突出,F1分数达0.71,而代码覆盖率预测在各语言间保持均衡表现。
效率对比凸显技术优势。传统方法处理相同测试量需数日,而RM-RF仅需数小时即可完成,速度提升达数十倍。这种效率跃升类似于从传统烤箱到微波炉的变革,不仅缩短等待时间,更显著降低能耗。在错误识别方面,模型对构造函数错误、未定义实体等常见问题判断精准,但对依赖缺失等复杂问题的识别仍需改进。
实际应用场景展现三大价值。首先在大规模测试生成中,开发者可先生成海量候选测试,再通过模型快速筛选优质用例;其次在强化学习训练中,模型能提供实时质量反馈,加速学习进程;最后在持续集成环节,可作为预检查工具减少无效测试运行。研究团队特别强调,中等规模模型(70亿参数)在完整微调下表现最优,说明任务适配性比单纯追求模型规模更重要。
技术细节揭示创新本质。模型通过分析原始代码(主食材)、现有测试(调味料)和新增测试(新调料)的组合关系,预测整体测试效果。这种文本分析方式突破了传统执行依赖,为性能预测、内存分析等场景开辟新路径。研究团队在数据收集阶段即注重质量把控,从GitHub精选活跃项目,确保代码时效性和多样性,同时避免与训练数据重叠。
当前研究已展现实用潜力。在真实项目测试中,RM-RF的预测准确性与传统方法持平,但效率实现数量级提升。这种"不运行即评估"的模式,为软件开发引入智能预判机制,犹如为程序员配备实时辅导系统,在编写测试时即可获得优化建议,无需等待漫长编译过程。研究团队正探索将模型集成到强化学习流程,实现端到端验证,并计划扩展更多编程语言支持。