春节前后,人工智能领域迎来一场前所未有的模型发布潮。谷歌、DeepSeek、智谱、MiniMax、阿里、字节跳动等科技巨头与新锐企业,几乎在同一时间推出各自新一代大模型,形成一场激烈的“技术公演”。这场密集发布不仅标志着行业进入主动竞争阶段,更反映出市场对AI商业化落地的迫切期待。
去年此时,DeepSeek V3的意外发布曾引发全球对AI算力格局的重新审视,而今年,头部厂商已不再满足于被动等待“爆款时刻”。从视频生成到图像处理,从编程模型到多模态交互,各家纷纷展示技术突破,试图在年初抢占市场心智。一位投资人指出,春节是资本、产业与用户重新评估AI价值的关键节点,谁能在此期间展示最清晰的技术路线与应用场景,谁就能在新一轮竞争中占据先机。
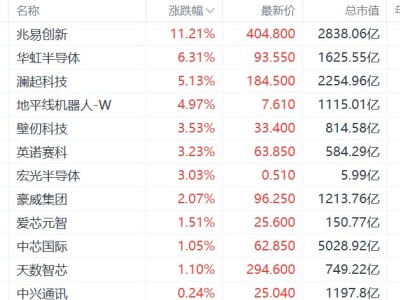
字节跳动在此次发布潮中表现尤为突出。其推出的Seedance 2.0视频模型,不再局限于画质提升,而是通过自动分镜、原生音画同步等技术,实现多镜头叙事与跨场景一致性,使视频生成具备“导演思维”。海外用户反馈显示,该模型在可控性上已跨越实用门槛,甚至被游戏科学创始人冯骥誉为“地表最强”。与此同时,豆包大模型2.0在数学推理能力上超越Gemini 3 Pro,且成本仅为后者的十分之一,进一步凸显其商业化潜力。
阿里则聚焦图像模型的办公化能力。其发布的Qwen-Image-2.0支持超长文本输入与复杂指令理解,可直接生成PPT与信息图,定位从“生成图片”转向“替代设计流程”。市场传言其新一代模型Qwen3.5即将发布,或包含开源的2B密集模型与35B MoE模型,显示阿里在开源生态上的投入力度持续加大。
谷歌的升级策略则瞄准科研与工程场景。其Gemini 3 Deep Think被定位为“推理基础设施”,在物理、化学等科学问题中展现实际能力,并通过API向研究人员开放。这一举措意味着谷歌不再满足于模型性能展示,而是试图将AI嵌入高价值生产流程。
DeepSeek的动向同样引发关注。其正在测试的长文本模型支持1M上下文,远超当前API服务的128K限制。市场期待其V4模型通过mHC与Engram技术突破算力瓶颈,推动AI应用商业化落地。野村证券报告指出,V4的核心价值不在于引发算力需求恐慌,而在于通过底层创新实现技术普惠。
MiniMax与智谱则将赌注押在Agent能力上。MiniMax推出的M2.5编程模型,以10B激活参数量实现高性能与高吞吐,直接对标国际顶尖模型,发布当日市值一度突破1800亿港元。智谱的GLM-5则通过引入稀疏注意力机制,在保持长文本处理效果的同时降低部署成本,其真实编程体验已逼近Claude Opus 4.5水平。
从技术趋势看,底层架构创新正成为竞争分水岭。无论是DeepSeek的系统效率优化,还是MiniMax的参数量压缩,均指向通过算法突破算力与内存约束。与此同时,多模态能力呈现明显的工作流化趋势:视频模型具备创作引擎属性,图像模型理解结构化办公需求,编程模型支持复杂工程场景。这些突破表明,AI正从单点工具向完整生产流程延伸。
资本的态度也在悄然转变。一位美元基金投资人表示,去年市场关注参数规模与训练成本,今年则更看重Agent、工作流与生产力,反映资本对商业化落地的真实需求。随着推理成本下降,应用层的商业探索空间逐步打开,谁能率先将技术转化为业务流程中的可用性,谁就能在竞争中脱颖而出。
这场春节档的模型发布潮,本质上是行业对技术路线的一次集体校准。从“模型更强”到“如何落地”,从基准成绩到生产稳定性,竞争维度的转移预示着AI发展进入新阶段。接下来的关键,在于谁能持续拿出真正进入生产环境的能力,而非停留在PPT上的领先。