近日,Moonshot的Kimi K2在GroqCloud平台上推出了预览版本,吸引了大量开发者的关注。他们纷纷好奇,Groq是如何做到让拥有1万亿参数的模型运行得如此迅速的。
传统硬件常常让开发者陷入两难境地:追求更快的推理速度往往意味着质量的妥协,而追求高精度则可能导致无法接受的延迟。这种权衡的根源在于,GPU架构主要针对训练工作负载进行优化。相比之下,Groq的LPU(逻辑处理单元)专为推理设计,能够在保持高质量的同时,消除造成延迟的架构瓶颈。
Groq通过其独特的TruePoint数值技术,打破了传统加速器的局限。传统加速器通过激进量化来提升速度,这通常意味着模型被压缩到INT8或更低精度,从而引入累积误差,导致质量下降。而TruePoint技术仅在不影响准确度的区域降低精度,结合LPU架构,能够在保持高精度数值的同时,确保模型质量。TruePoint格式支持100位中间累积,提供足够的范围和精度,无论输入位宽如何,都能实现无损累积。这意味着权重和激活函数可以以较低精度存储,而所有矩阵运算则以全精度执行,然后根据下游误差敏感度选择性地量化输出。
Groq的编译器策略性地应用不同精度,例如,在需要高准确性的注意逻辑中使用FP32,在混合专家(MoE)权重中使用块浮点而不影响稳健性,以及在容错层中存储FP8激活。这种精度控制策略使得速度比BF16提升了2至4倍,同时在MMLU和Humaneval等基准测试中保持了准确率。
内存架构方面,传统加速器沿用为训练设计的内存层级结构,依赖DRAM和HBM作为主存储,这些存储介质在每次权重提取时都会引入数百纳秒的延迟。这对于需要按顺序执行层且运算强度较低的推理任务来说,是不利的。而Groq的LPU集成了数百兆片上SRAM作为主权重存储器,显著降低了访问延迟。这种设计允许计算单元以全速加载权重,并通过将单层拆分到多个芯片上实现张量并行,为快速、可扩展的推理带来实际优势。
在执行模型方面,GPU架构依赖于动态调度,这引入了非确定性延迟。而Groq的编译器预先计算整个执行图,包括芯片间通信模式,直至单个时钟周期。这种静态调度消除了缓存一致性协议、重新排序缓冲区、推测执行开销和运行时协调延迟,实现了确定性执行。这进一步支持了两项关键优化:无尾延迟的张量并行和张量并行之上的流水线并行。
Groq的并行策略专注于延迟优化分布。数据并行通过运行多个模型实例来扩展吞吐量,适用于提高整体处理能力,但对于单个响应的等待时间并无帮助。而张量并行通过将单个操作分布在多个处理器上来降低延迟,这对于实时应用至关重要。Groq的LPU架构专为张量并行而设计,将每一层划分到多个LPU上,从而加快单次前向传递的速度。
Groq还采用了推测解码技术,利用较小的“草稿”模型预测未来令牌序列,并在较大的目标模型中进行验证。在传统硬件上,验证步骤通常受内存带宽限制,而在Groq的LPU上,通过流水线并行可以更高效地处理推测性token批次的验证,从而加快处理速度。
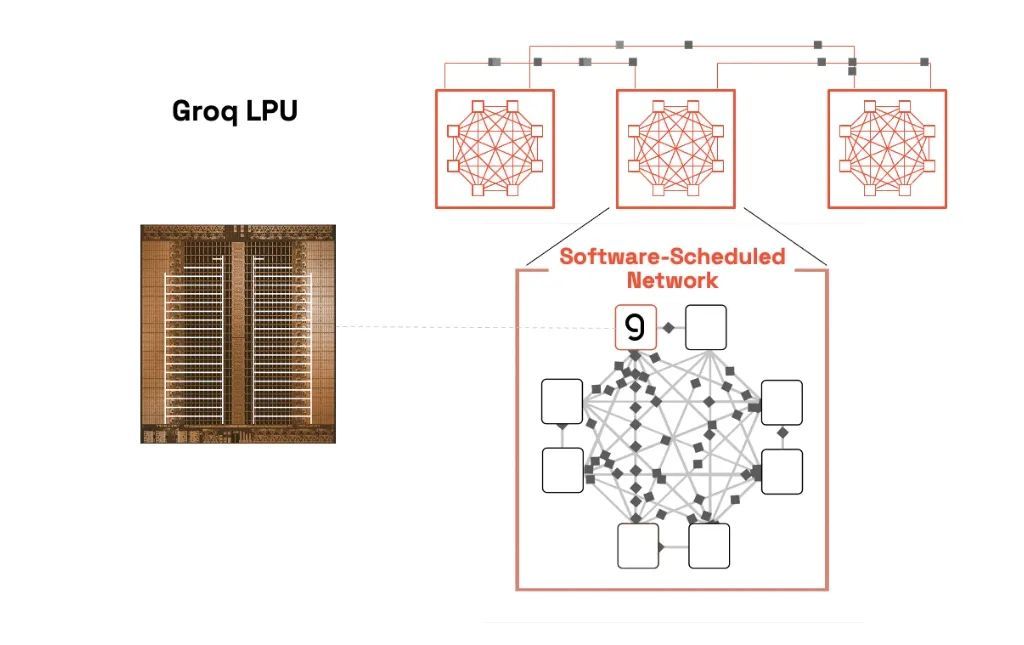
软件调度网络方面,Groq使用准同步芯片间协议来消除时钟漂移,并将数百个LPU对齐,使其充当单个核心。这样,软件编译器可以准确预测数据到达时间,支持时序推理。周期性软件同步不仅支持计算调度,还支持网络调度,使Groq能够像单核超级集群一样运行,避免了传统架构中的复杂协调问题。
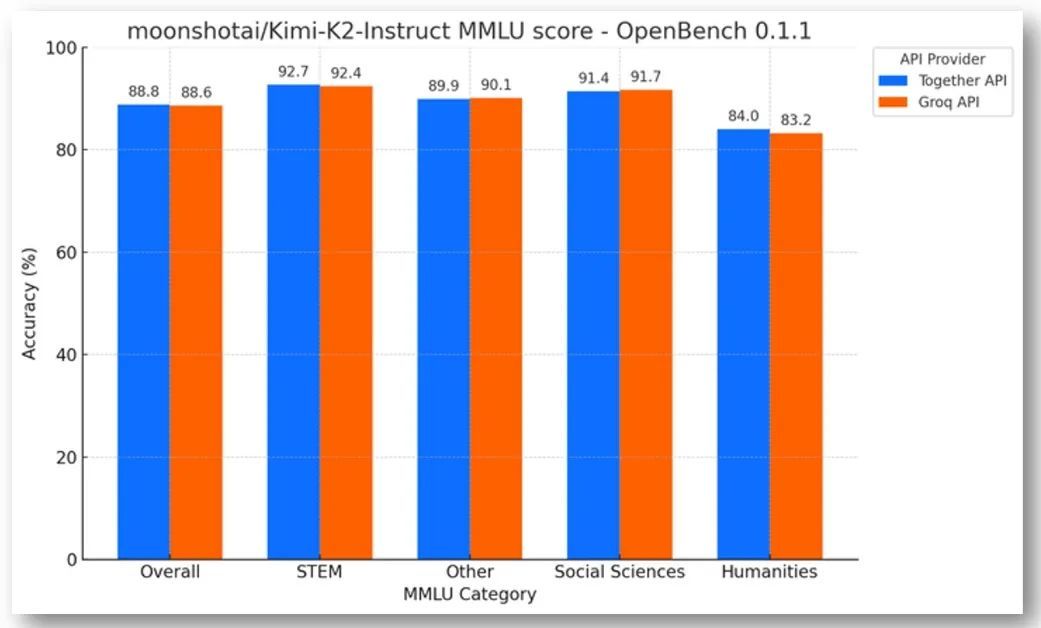
在基准测试方面,Groq表现出了卓越的性能。他们发布了OpenBench,一个与提供商无关的、面向大型语言模型(LLM)的开放评估框架。在Groq和基于GPU的API提供商上运行Kimi-K2-Instruct的OpenBench 0.1.1 MMLU实现,结果显示准确率得分很高,充分展现了Groq堆栈的强大功能。
Groq从零开始构建推理系统,力求速度、规模、可靠性和成本效益。正因如此,他们能够在短时间内让Kimi K2的性能实现显著提升。Groq高度重视开发者反馈和实际性能,结合行业领先的设计和严格的技术基准,致力于提供极致的AI推理体验。他们将继续加速硬件和软件的开发,让开发者能够专注于快速构建应用。