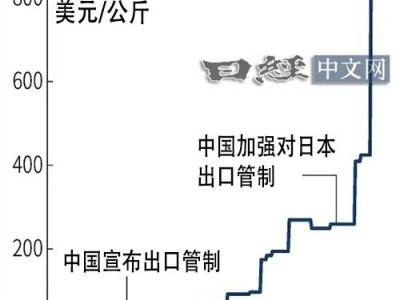
在人工智能(AI)领域,各类大语言模型的发布与比拼已经成为社交媒体上的热门话题。每隔一段时间,我们就能见到诸如“XX模型刷新多项基准测试记录,超越众多闭源竞品”或“国产XX模型登顶中文评测榜首”的新闻。这些消息引发了公众的广泛关注,同时也引发了对于模型评估标准的深入探讨。
AI模型的“登顶”究竟意味着什么?这些评测的权威性和公正性如何保证?为何不同平台的排名存在差异?对于这些问题,公众普遍感到困惑。事实上,理解这些排行榜背后的“游戏规则”,是洞察AI领域竞争态势的关键。
首先,我们来看看一类被称为“客观基准测试”的评测方法。这类测试类似于人类的高考,通过一系列标准化的题目来评估AI模型在特定任务上的表现。例如,Artificial Analysis平台推出的AAII指数,就是一项综合了多个前沿能力单项评测结果的指标。它涵盖了知识推理、数学和编程等多个领域,能够全面反映AI模型的智能水平。
在知识推理方面,MMLU-Pro、GPQA Diamond和Humanity's Last Exam等测试,分别从不同角度考察了模型的专业知识广度、深度推理能力和跨学科问题解决能力。在编程领域,LiveCodeBench和SciCode等测试则关注模型的编程鲁棒性、处理边界情况的能力以及对科学原理的理解。而在数学领域,AIME和MATH-500等测试则衡量了模型在高级数学推理和解题能力上的表现。

然而,客观基准测试虽然具有客观、高效、可复现的优点,但也存在局限性。一方面,模型可能因数据污染而在测试中取得高分,但在实际应用中表现不佳。另一方面,这类测试往往难以衡量模型的“软实力”,如创造力、情商、幽默感和语言优美程度等。
为了弥补这一缺陷,另一类评测方法——“人类偏好竞技场”应运而生。这类评测通过众包平台,让用户对模型的表现进行投票,从而选出更符合人类需求的模型。LMSys Chatbot Arena就是一个典型的例子。在这个平台上,两个模型同时对一个问题进行解答,用户根据自己的判断选择最合适的回答。这种评测方法消除了刻板偏见,能够更真实地反映模型在实际应用中的表现。

不过,人类偏好竞技场也存在一些问题。例如,评测主要采取单轮对话的方式,难以充分评估需要多轮对话的任务;投票者可能存在偏差,无法覆盖所有用户群体;评测结果过于主观,难以保证客观性和公正性;用户在评判时往往更关注答案的表述,而忽视了回答内容的真实性。
面对琳琅满目的AI模型排行榜,用户应该如何选择?事实上,没有任何一个排行榜是绝对权威的。排行榜只是参考,用户需要根据自己的应用场景和需求来选择模型。例如,程序员可能更关注模型的代码编写和修复能力;大学生可能更看重模型的文献综述和学术解释能力;而营销人员则可能更看重模型的文案创作和创意构思能力。
因此,在AI领域,用户需要保持理性思考,不被排行榜的喧嚣所干扰。大模型是工具而非神祇,看懂排行榜是为了更好地选择工具。用户应该将实际问题交给模型进行尝试,哪个模型能够最高效优质地解决问题,哪个模型就是用户的“私人冠军”。