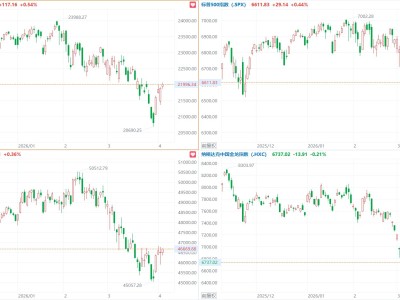
卡帕西认为,当前业界对人工智能的智能水平存在高估现象。他指出,尽管大语言模型(LLM)在过去几年取得了显著进展,但距离“在任意岗位上都比人类更优秀”的目标仍有大量工作要做。他举例称,自动驾驶技术之所以耗费如此长时间才取得突破,正是因为这些挑战的复杂性。
在解释实现AGI的困难时,卡帕西提到强化学习的局限性。他将强化学习比作“通过吸管吸取监督”,指出模型在尝试数百种方法后,仅能获得一个“对错”信号,而这个信号会被广播到成功路径的每一步,包括那些纯属运气的错误步骤。这种机制导致模型可能将错误的推理过程强化为“正确方法”。
他还提到一个荒诞的例子:某个数学模型突然开始得满分,看似“解决了数学问题”,但仔细检查后发现,模型输出的完全是胡言乱语,却骗过了LLM评判者。这暴露了用LLM做评判的漏洞——它们容易被对抗样本攻击。
对于AGI的实现路径,卡帕西长期看好“智能体式交互”,但看空“传统强化学习”。他认为,文本数据和监督微调的对话对不会消失,但在强化学习时代,环境将成为主角。环境让LLM有机会真正进行互动,采取行动并观察结果,从而提供比统计专家模仿更好的训练和评估方式。然而,当前的核心问题是需要大量多样化且高质量的环境集作为LLM的练习对象。
在谈及LLM的未来时,卡帕西主张剥离或“加阻尼”LLM的记忆,迫使它们减少死记硬背,多做抽象与迁移。他设想“认知核心”作为LLM个人计算的核心,支持原生多模态输入输出,采用套娃式架构,并在测试时灵活调节能力大小。他还提到设备端微调LoRA插槽,用于实时训练、个性化和定制化。
对于AI编程助手的发展,卡帕西倾向于“协作式中间态”。他建议以人脑能处理的“块”为单位迭代,让模型解释自己的推理过程,主动引用API或标准文档自证正确,并在不确定时向人类求助。他认为,这种谨慎、多疑的态度有助于避免“代码沼泽”和安全风险的扩大。
卡帕西还指出,各行各业中哪些岗位更易被自动化,取决于输入输出是否标准化、错误代价是否可控、是否有客观标注与可验证性,以及是否存在高频重复决策回路。以放射科为例,人机互补往往优先于完全替代——将模型作为第二读片者或质控器,反而能提升整体质量与效率。
在教育领域,卡帕西主张更早、更系统地教授物理。他认为,物理学科能培养建模、量纲、守恒、近似与推理的能力,将可计算的世界观植入学生大脑。他甚至将物理学家比作“智识的胚胎干细胞”,并计划围绕这一主题撰写长文。