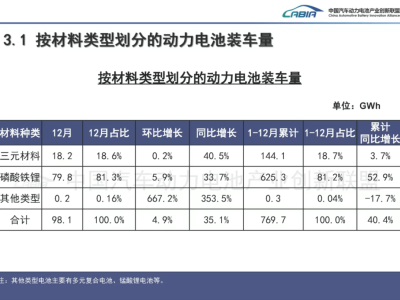
AI领域近期因DeepSeek推出的新型小模型引发广泛关注。这款仅含30亿参数的DeepSeek-OCR模型,虽然参数规模远小于主流大模型,却在信息处理效率上展现出突破性成果。研究团队通过实验证明,AI在处理文档信息时,采用视觉理解方式比传统文本处理更具效率优势。
在信息处理成本方面,该模型展现出显著优势。以中文文本为例,传统方法处理千字文档需消耗约1000个文本token,而DeepSeek-OCR通过视觉编码技术,仅需100个视觉token即可达到97%的精度还原。即使将压缩比提升至20倍,仍能保持60%的核心信息准确率。这种压缩效率犹如将整箱书籍精简为便携笔记,既节省空间又保留关键内容。
技术实现的核心在于团队自主研发的DeepEncoder编码器。该系统采用三级处理机制:首先通过窗口注意力机制分块解析内容,继而通过16倍压缩模块去除冗余信息,最后经全局注意力提取核心要素。这种处理方式类似于图书馆的分类管理,将常用书籍置于显眼位置,非常用资料归档存储,在保证检索效率的同时优化存储空间。
与市面主流OCR工具的对比测试显示,上海人工智能实验室2025年发布的MinerU2.0模型处理单页文档需6000余token,而DeepSeek-OCR仅用不足800token即达更优效果。这种差异相当于用小型货车完成原本需要重型卡车运输的任务,且运输质量更高。
研究团队在实验过程中发现意外收获:当信息压缩比达20倍时,低分辨率图像的识别精度下降现象,与人类记忆的衰退规律高度吻合。这种发现促使他们构建出独特的记忆模拟机制——将对话历史按时间远近编码为不同分辨率的视觉token,近期对话保持高清,远期对话逐步压缩,既节省计算资源又符合实际使用需求。
团队的创新思维在模型架构上体现得尤为明显。不同于传统OCR专注识别精度提升,他们将研究重心转向信息压缩的本质问题。这种思路延续了其在MoE架构上的突破——通过"共享专家+路由专家"的组合设计,用5.7亿激活参数实现超越百亿参数模型的效果。
该模型的技术路径突破了传统框架,通过视觉理解重构信息处理范式。这种创新不仅体现在参数效率上,更在于对AI认知本质的探索。当行业还在追求模型规模时,DeepSeek已转向研究如何让AI在资源约束下实现智能决策,这种差异化策略或许正预示着下一代AI技术的发展方向。