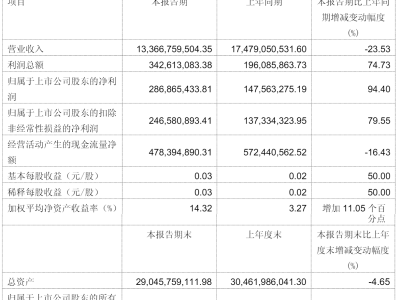
谷歌旗下DeepMind团队近日发布了一款名为SIMA2的多模态智能体研究预览版,该系统基于Gemini2.5Flash-lite架构开发,在未接触过的复杂环境中执行指令的成功率较前代提升近一倍,同时展现出通过自我优化持续提升性能的能力。研究团队强调,此次发布的核心目标是验证构建通用机器人与通用人工智能(AGI)所需的高层次环境理解与推理机制。
在技术实现层面,SIMA2延续了利用数百小时游戏视频进行预训练的策略,但创新性地引入了自生成数据闭环系统。当智能体进入新场景时,会调用独立的Gemini模型批量生成多样化任务,随后通过内置的奖励模型评估任务完成质量,筛选优质轨迹数据用于持续微调。这种无需人工标注的自主学习机制,使系统在《无人深空》等测试场景中能够通过解析环境文本、识别颜色符号等视觉信息,自主执行"前往红色建筑"或"采集特定资源"等复杂指令,甚至支持由emoji组合构成的抽象指令。
演示实验中,研究团队结合生成式世界模型Genie为SIMA2动态创建逼真的户外场景。智能体不仅准确识别出长椅、树木、蝴蝶等环境元素,还能根据指令与这些对象产生交互。高级研究科学家简·王指出,这种"环境感知-目标推断-动作规划"的完整决策链,正是将虚拟环境训练成果迁移至实体机器人的关键技术模块。通过模拟环境中的反复验证,团队希望为真实机器人系统构建可复用的认知框架。
值得注意的是,当前版本的SIMA2专注于高层次决策能力的开发,暂未涉及机械关节控制、运动协调等底层执行技术。DeepMind同时训练的机器人基础模型采用完全不同的技术路径,两种系统的融合方案仍在探索阶段。研究团队拒绝透露正式版本的发布时间表,但表示希望通过开放预览版吸引外部合作,共同研究虚拟智能体向物理实体迁移的技术路径。目前该系统已展现出在动态环境中理解复杂指令的潜力,但其商业化应用仍需突破多项技术瓶颈。