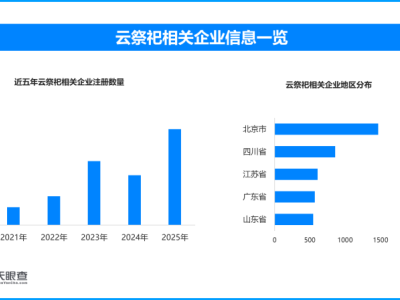
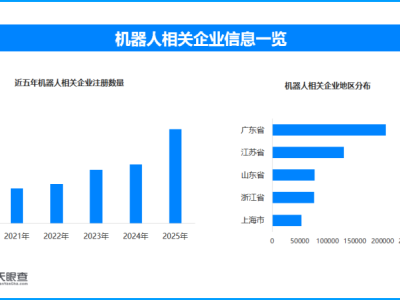
数学推理领域迎来重要突破,DeepSeek团队近日推出新型模型DeepSeekMath-V2,其独特的自我验证训练框架为构建可靠数学智能系统开辟了新路径。该模型在多项国际顶级数学竞赛中取得惊人成绩,包括国际数学奥林匹克竞赛(IMO)和中国数学奥林匹克竞赛(CMO)的金牌水平,以及普特南数学竞赛118/120的超高得分,充分展现了其强大的数学推理能力。
传统强化学习方法在数学推理训练中存在明显短板。这类方法仅通过最终答案与标准答案的匹配程度进行奖励,完全忽视了推理过程的质量。研究团队指出,正确答案并不等同于正确推导,尤其在定理证明任务中,严格的逻辑推导过程远比数值答案重要。针对这一难题,DeepSeekMath-V2构建了自驱动的验证-生成闭环系统,通过两个大语言模型(LLM)的协作实现突破性创新。
该系统的核心架构包含"作者"与"审稿人"两个角色:一个LLM负责生成数学证明,另一个则担任验证器进行审查。两者通过强化学习机制形成闭环,并引入独特的"元验证"层来抑制模型幻觉。实验数据显示,元验证机制的引入显著提升了验证器的分析质量评分,同时保持了证明评分预测的准确性,实现了验证精度与可靠性的双重提升。这种创新设计使模型能够自主识别证明过程中的真实缺陷,而非仅仅依赖最终答案的正确性。
为解决人工标注成本高昂的问题,研究团队开发了高效的自动化评估流程。该系统基于多层验证机制,通过交叉检验与共识决策确保标注准确性。具体实施中,系统会对每个证明进行多轮独立分析,并对识别出的问题进行二次验证,最终依据共识结果给出质量评分。在后续训练阶段,这一自动化流程已能完全替代人工标注,其评估结果与专家判断高度一致,为模型持续优化提供了高质量训练数据。
这种自驱动学习生态系统的构建具有重大意义。系统通过验证反馈直接优化生成质量,利用自动化评估处理复杂案例,并持续产生训练数据促进迭代升级。研究显示,该技术路径不仅显著降低了人力成本,更证明了在适当技术支持下,人工智能系统能够实现自我演进与持续改进。这一发现为下一代自主学习系统的开发奠定了重要技术基础。
基准测试结果进一步验证了模型的领先性能。在自主构建的91个CNML级别问题测试中,DeepSeekMath-V2在代数、几何、数论、组合学和不等式等所有类别中均超越了GPT-5-Thinking-High和Gemini 2.5-Pro等知名模型。在IMO-ProofBench基准测试中,该模型在基础集上的人工评估结果优于DeepMind的DeepThink(IMO金牌水平),在更具挑战性的高级集上也保持强劲竞争力,同时显著超越其他基准模型。
特别值得关注的是验证机制的有效性测试。对于未完全解决的问题,生成器能够准确识别证明过程中的真实缺陷;对于完全解决的问题,则成功通过了全部64次验证尝试。这一结果表明,基于大语言模型的验证器确实能够有效评估那些传统上被认为难以自动验证的复杂数学证明。研究团队表示,模型代码与权重已在Hugging Face及GitHub平台开源发布,期待与全球研究者共同推进数学智能系统的发展。