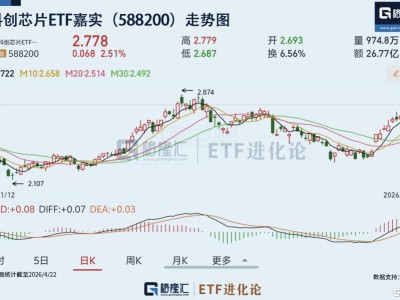
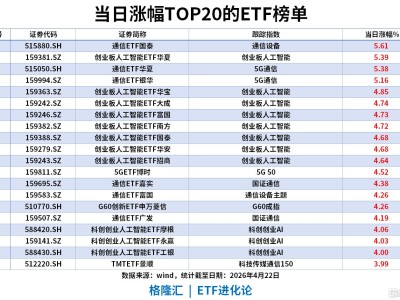
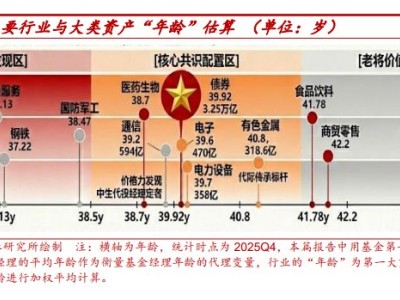
近期,开源社区因DeepSeek的一项新动向掀起热议。其FlashMLA代码库频繁更新,一款名为Model1的模型悄然进入公众视野,引发关于DeepSeek下一代旗舰模型的猜测。结合代码变更与社区分析,这款神秘模型的技术细节逐渐浮出水面。
在代码库的分支结构中,Model1与DeepSeek-V3.2并列存在,形成独立的技术路径。这一布局暗示其并非V3系列的迭代补丁,而是基于全新架构的工程版本。技术专家通过解析代码差异发现,Model1在核心参数设计上与V3系列存在显著差异,例如将MLA架构的head_dim从576维调整为512维。这种“标准化”回归可能旨在优化与NVIDIA Blackwell架构的算力匹配,同时提升Latent压缩效率。
硬件适配层面,代码库新增大量针对Blackwell GPU的优化模块。例如,api.cpp文件中出现的FMHACutlassSM100FwdRun接口,直接指向下一代GPU的核心指令集。根据运行环境说明,Model1在B200芯片上需CUDA 12.9支持,其Sparse MLA算子已实现350 TFlops的初步性能,而H800芯片上的Dense MLA吞吐量则高达660 TFlops。这种跨代硬件的针对性优化,进一步印证了Model1的旗舰定位。
算子创新是Model1最突出的技术突破。测试脚本显示,该模型同时支持Sparse与Dense两种解码模式,其中Sparse路径采用FP8精度存储KV Cache,计算时动态切换至bfloat16以保证精度。这种混合精度设计可显著降低长文本推理的显存占用,同时维持计算效率。社区推测,此特性或使Model1在处理超长上下文时具备优势。
代码注释中隐现的两大新机制引发关注。首先是Value Vector Position Awareness(VVPA),该技术可能通过增强位置编码的动态适应性,解决传统MLA架构在长文本中的信息衰减问题。其次是Engram机制,尽管具体实现未完全公开,但结合分布式存储相关的代码逻辑,其或为KV Cache压缩提供的全新解决方案,与Model1的高吞吐需求形成技术闭环。
目前,DeepSeek尚未对Model1的官方身份作出回应。但技术社区普遍认为,从架构参数、硬件适配到算子设计,Model1均展现出跨越V3系列的技术特征。按照DeepSeek的版本命名惯例,V3.2之后的架构代际升级,极有可能以V4命名。这款神秘模型是否会成为春节前后的技术惊喜,仍需等待官方确认。