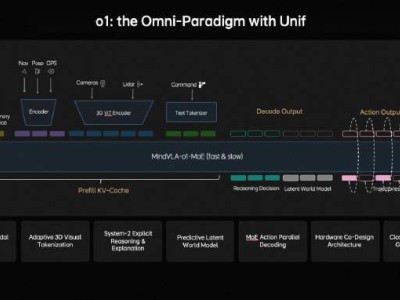
近期,人工智能领域的一项新研究在学术界引起了广泛讨论。亚利桑那州立大学的一组研究人员在预印本平台arXiv发布了一篇论文,对大型语言模型如ChatGPT的理解提出了新视角。他们质疑,这些被广泛认为具备思考或推理能力的AI模型,实际上可能只是在执行数据相关性的匹配任务。
论文详细阐述了研究小组的发现。他们指出,尽管这些AI模型在解答问题时往往会展示出一系列看似逻辑连贯的中间步骤,但这并不等同于真正的推理过程。相反,这些模型更像是在进行大规模的数据相关性计算,而非理解或推断因果关系。
研究小组进一步强调,将AI模型的行为拟人化,可能会误导公众对其内在机制的正确理解。他们通过对比一些高性能的推理模型,如DeepSeek R1,来说明这一点。尽管这些模型在某些特定任务上表现出色,但这并不意味着它们具备人类的思考能力。实际上,AI的输出结果并没有包含真正的推理步骤。
这一发现对于当前高度依赖AI技术的社会具有重要意义。研究人员提醒,用户在依赖AI模型进行决策时,应当对其能力保持审慎态度。AI模型生成的中间步骤,尽管看似合理,但可能并不反映真正的推理过程,这可能会导致用户对AI的问题解决能力产生过度乐观的误判。