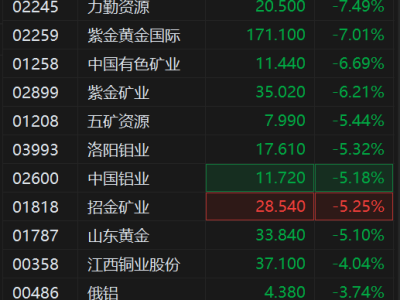
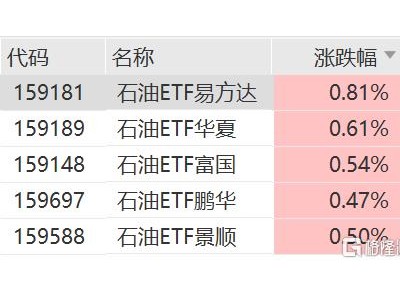
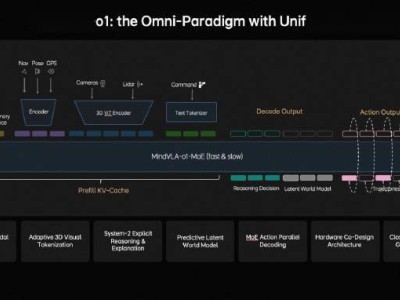
近期,一项由苹果公司与杜克大学携手推出的创新强化学习方法“交错推理”,在人工智能领域掀起了波澜。该方法旨在显著增强大语言模型的推理能力,为复杂问题的解决提供了新的视角。
在探讨这一突破之前,我们不得不提及当前大语言模型在处理多步骤复杂问题时所面临的挑战。它们往往遵循一种线性的“思考-回答”模式,虽然逻辑清晰,但响应速度较慢,且在推理链的任一环节出错都可能影响最终答案的准确性。这种模式与人类的交流方式大相径庭,人类倾向于在思考过程中逐步表达想法,而模型则倾向于在完成整个推理后才给出答案,这在一定程度上限制了其效率和互动性。
为了打破这一僵局,“交错推理”应运而生。该方法的核心在于,在模型的推理过程中,巧妙地交替进行内部计算和输出中间答案的操作,从而大幅提升响应速度和实用性。为了实现这一目标,研究团队设计了一个基于强化学习的训练框架,其中嵌入了特定的指示标签,这些标签能够引导模型在达到关键推理节点时输出阶段性成果。

为了确保模型在追求局部输出效率的同时,不牺牲整体推理的准确性,研究团队精心构建了一套基于规则的奖励机制。该机制综合考虑了格式合规性、最终准确率以及条件性中间准确率等多个维度,以确保模型在推理过程中的每一步都能得到恰当的激励。
实验数据表明,“交错推理”在Qwen2.5模型(包括1.5B和7B参数版本)上取得了显著成效。与传统方法相比,该方法的响应速度提升了超过80%,推理准确率也提高了近19.3%。更令人振奋的是,尽管模型仅在问答类和逻辑类数据集上进行了训练,但它在MATH、GPQA和MMLU等更具挑战性的任务中也展现出了强大的泛化能力。
研究团队还尝试了多种奖励机制,包括全或无奖励、部分积分奖励及时间折扣奖励等。结果显示,条件性奖励和时间折扣奖励的效果最为突出,远远超越了传统训练方式。
“交错推理”的提出,不仅为提升大语言模型在复杂推理任务中的表现提供了一条切实可行的技术路径,也为未来模型的设计与优化提供了新的思路。这一创新成果无疑将推动人工智能领域向更加高效、智能的方向发展。