在今年的国际计算语言学年会(ACL)上,传来了一则令人瞩目的消息:2025年度的获奖论文中,中国作者的比例首次超过了51%,占据了半壁江山,而紧随其后的美国作者比例仅为14%。这一数据不仅彰显了中国在计算语言学领域的强大实力,也预示着该领域未来可能的发展趋势。
在众多获奖论文中,由DeepSeek的梁文锋担任通讯作者,并与北京大学等机构联合发表的一篇论文尤为引人注目。该论文不仅荣获了Best Paper奖,其研究成果更是引发了业界的广泛热议。论文的第一作者袁境阳,在会议现场的讲座中透露,他们团队所研发的技术能够将上下文长度扩展至100万tokens,并计划将这一技术应用于DeepSeek的下一代前沿模型中。袁境阳在撰写这篇论文时,还只是DeepSeek的一名实习生。

该论文的核心在于提出了NSA(Natively trainable Sparse Attention,原生可训练稀疏注意力)机制,旨在解决长上下文建模中面临的高计算成本挑战。随着序列长度的增加,传统的注意力机制在计算延迟上遇到了瓶颈。为此,该团队提出了两项核心创新:一是通过算术强度平衡的算法设计,结合硬件对齐优化,实现了显著的加速效果;二是通过高效算法和反向算子,实现了稳定的端到端训练,降低了预训练的计算量。
实验结果表明,NSA机制在保持模型性能的同时,实现了显著的速度提升。在真实世界语言语料库上的综合评估中,NSA由于稀疏性过滤掉了更多噪声,从而在基准测试中产生了更好的准确率。该团队在拥有270亿参数的Transformer骨干网络上进行了预训练,并从多个方面评估了NSA的性能。实验数据显示,在9项指标中的7项上,NSA均超过了包括全注意力模型在内的所有基线。
特别是在推理相关的基准测试中,NSA取得了显著提升。这得益于其分层稀疏注意力设计,该设计结合了用于高效全局上下文扫描的token压缩和用于精确局部信息检索的token选择。这种设计使得NSA能够在较长序列上充分发挥其效率优势,同时展现出强劲的性能。
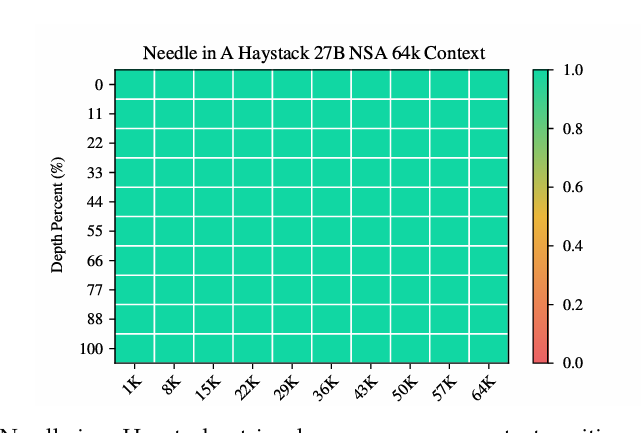
NSA在需要对长上下文进行复杂推理的任务上也表现出色。在多跳问答任务、代码理解任务和段落检索任务上,NSA均超过了基线模型。这些结果验证了NSA处理各种长上下文挑战的能力,也证明了其作为通用架构的稳健性。
据袁境阳透露,虽然这篇论文早在今年2月就对外公布,但相关研究成果尚未应用于任何DeepSeek模型中。不过,他透露DeepSeek的下一代模型将应用这项技术。这一消息引发了业界对DeepSeek V4发布的期待。此前,已有传言称DeepSeek R2可能提前泄露,但DeepSeek官方一直未对此作出回应。而此次ACL获奖论文的发表,无疑为DeepSeek的下一代模型增添了更多看点。