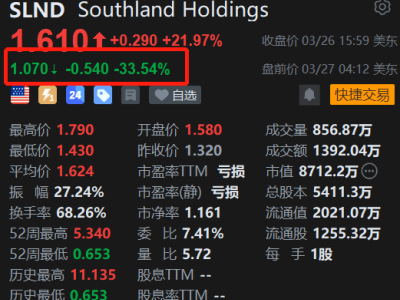
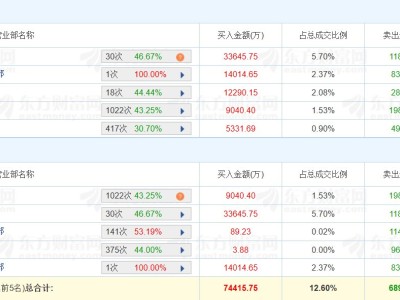
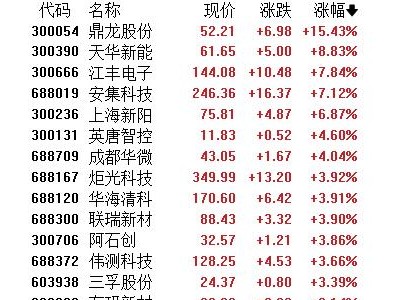
智谱AI近期震撼发布了其最新一代的视觉推理模型GLM-4.5V,并慷慨地选择将此模型在GitHub、Hugging Face及魔搭社区上以MIT开源协议进行共享,此举不仅展现了其对技术开放的承诺,也为商业应用提供了无限可能。
GLM-4.5V,作为一个拥有庞大参数的VLM(视觉-语言模型),其总参数高达1,060亿,激活参数亦有120亿。该模型是在智谱AI的旗舰文本模型GLM-4.5-Air的基础上精心打造,并继承了GLM-4.1V-Thinking的技术精髓。值得注意的是,GLM-4.5V在41项公开的多模态基准测试中,均取得了同级别开源模型中的顶尖表现。
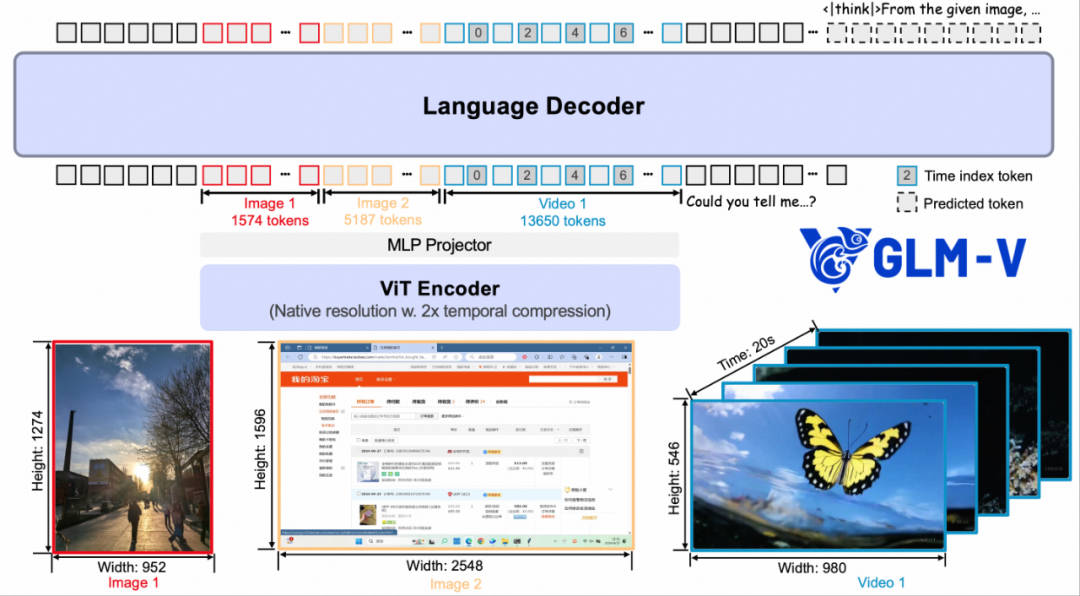
技术层面,GLM-4.5V由三大核心组件构成:视觉编码器、MLP适配器以及语言解码器。通过引入创新的三维旋转位置编码(3D-RoPE),模型对三维空间关系的理解及推理能力得到了显著提升。它能够处理包含64K tokens的多模态长上下文输入,并利用三维卷积技术,显著优化了视频处理效率。这一设计让GLM-4.5V不仅能处理静态图像,还能深入解析视频内容,对高分辨率及极端宽高比的图像同样展现出强大的处理能力和稳定性。
为了全面增强GLM-4.5V的多模态能力,智谱AI在模型训练的每个阶段都实施了精细的优化策略。预训练阶段,模型在庞大的图文交错多模态语料及长上下文内容的滋养下,建立了对复杂图文和视频内容的坚实基础。随后,在监督微调阶段,通过引入“思维链”格式的显式训练样本,进一步加深了模型的因果推理和多模态理解能力。最终,在强化学习阶段,借助多领域奖励系统,结合可验证奖励强化学习(RLVR)与人类反馈强化学习(RLHF),模型在STEM问题、多模态定位及智能体任务等多个领域均实现了显著提升。
GLM-4.5V的实际表现同样令人瞩目。在图像推理方面,它能够进行复杂的场景解析和多图综合判断。例如,它能根据用户的自然语言指令,准确识别图像中的目标物体,并标注出精确的位置坐标。更令人惊叹的是,它还能通过分析图像中的微小线索,如植被类型、气候痕迹及建筑风格,推断出照片的拍摄地点及大致地理位置,这一能力甚至超越了许多专业工具。
在复杂文档理解领域,GLM-4.5V同样展现出了卓越的能力。它能够处理包含大量图表的长文本,同步理解文字与图像信息,从而准确地进行内容总结、翻译及图表信息提取,有效避免了传统方法中可能出现的错误传递问题。针对前端开发及用户界面交互任务,GLM-4.5V还提供了“前端复刻”功能,通过分析网页截图或交互视频,能够生成相应的HTML、CSS及Javascript代码,完美复刻网页的布局、样式及交互逻辑。
GLM-4.5V的GUI Agent能力同样值得称道,它能够识别和处理电子屏幕画面,执行对话问答、图标定位等任务,为开发桌面环境智能体应用奠定了坚实基础。智谱AI还同步开源了一款桌面助手应用,该应用能够实时捕获屏幕信息,依托GLM-4.5V处理多种视觉推理任务,涵盖代码辅助、视频内容分析、游戏解答及文档解读等多个领域。