
在2025年世界人工智能大会的热闹氛围中,一款名为“量子1号”的通用轮式双臂机器人成为了智能终端展区H3馆的明星展品。这款机器人,与其同伴“小白”,以其出色的任务执行能力吸引了众多参展者的目光。在复杂的展会环境中,只需简单的语音指令,“小量”便能根据参观者的喜好,挑选对应颜色的香包材料,亲手制作出个性化的香囊,并精准地递送到他们手中。与此同时,“小白”则在家务整理区忙碌着,将垃圾准确分类投放,并将散落的衣物整理进脏衣篓,随后还主动将香囊材料补充到补货台,为“小量”的工作提供支持。

这两款机器人均出自自变量机器人(X Square Robot)之手,这是一家成立不到两年的新兴企业,却已迅速在具身智能与机器人技术领域崭露头角。自变量机器人的核心团队汇聚了全球顶尖的AI与机器人专家,致力于技术创新与发展。截至目前,该公司已完成7轮融资,累计金额超过10亿元人民币,融资速度和规模在国内具身智能领域均名列前茅。
自变量机器人的创始人兼CEO王潜,是一位在AI领域有着深厚学术背景的专家。他曾在清华大学获得学士和硕士学位,并在硕士期间发表了成为全球最早提出Attention机制的研究论文之一,该研究后来成为Transformer架构的核心。赴美深造后,他在美国南加州大学攻读博士学位,专注于机器人学习与人机交互研究。怀揣着对机器人技术的热情,他回国后创立了自变量机器人。
自变量机器人自研的完全端到端统一视觉-语言-动作(VLA)模型WALL-A,是实现机器人自主感知、决策与高精度操作的关键。该模型具有强大的泛化能力,能在部分未见过的物理场景中实现零样本泛化。通过具身思维链(CoT)技术,WALL-A能够将抽象任务拆解为可执行的子步骤,并根据实时变化调整行动策略。WALL-A采用统一架构,将视觉、语言、动作等所有模态信息转换为统一的token序列,送入Transformer核心进行端到端统一学习,使系统在面对新任务时能够像人类一样思考和工作。
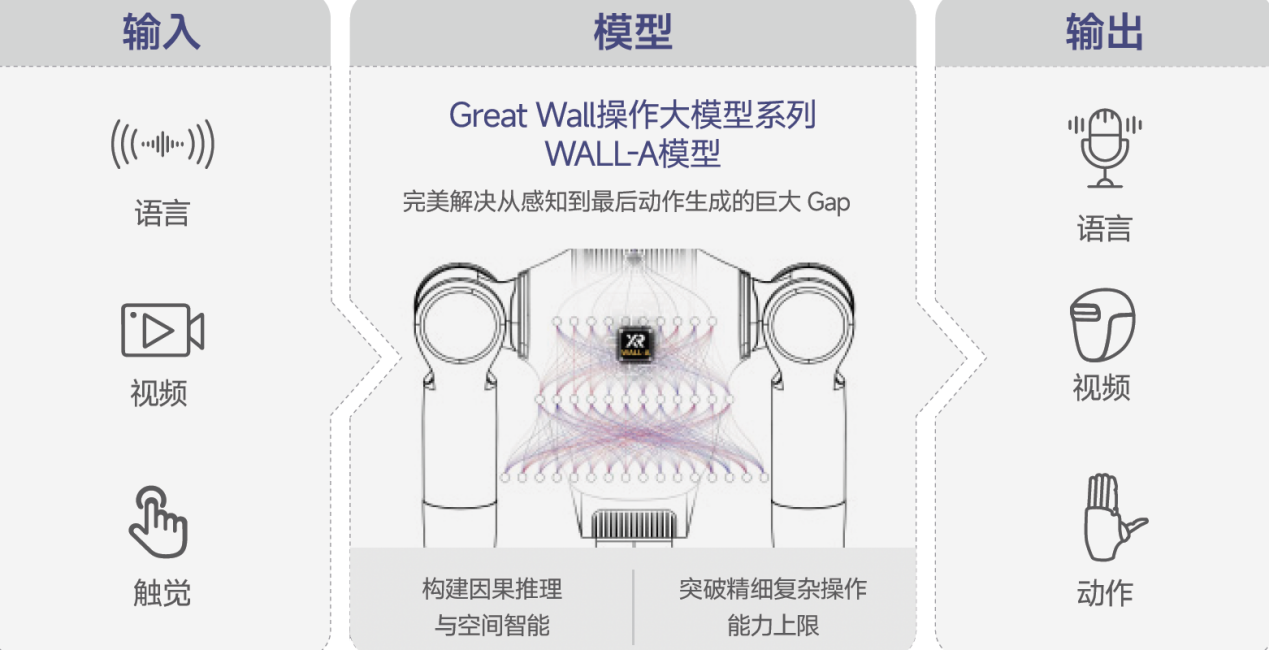
在展会前夕的短短几天内,WALL-A模型迅速学会了香囊制作等长流程柔性物体处理任务,展现了其在多机协作、跨任务切换及抗干扰场景中的卓越能力。在香囊制作任务中,WALL-A不仅自主完成了上下料、分拣、填充、贴标签等长序列流程,还成功处理了柔性物体与高度不可控环境,甚至在游客干扰下仍能保持稳定的工作状态。
自变量机器人在推出“量子1号”后,又迅速推出了新一代具身轮式仿人形机器人“量子2号”。与“量子1号”相比,“量子2号”在硬件上进行了升级,能够应对更高的负载操作需求。同时,其身高1.72米,臂展长度加上折叠式腰部设计,使其能够触及0-2米的工作空间,覆盖更全面的操作范围。“量子2号”还配备了交互屏,提供了更丰富的人机交互体验,更适配服务场景中的交互需求。
自变量机器人的两款机器人均采用轮式底盘构造,与传统双足机器人相比,在结构复杂性、成本和安全性方面具有优势。它们更适合在室内场景下工作,如酒店、零售店等泛商业场景,以及养老机构等康养场景。目前,自变量机器人已与多家头部酒店和养老机构合作探索落地场景,包括清洁任务、基础服务等。











