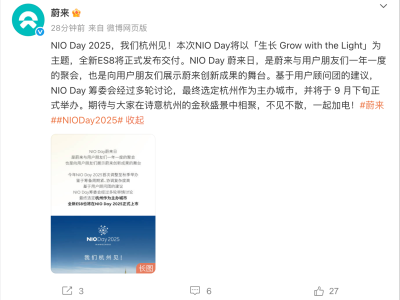
近日,人工智能领域的先锋公司Anthropic在其官方油管频道发布了一期深度视频,三位AI研究员围绕大语言模型(LLM)的思考机制展开了一场深入讨论。这次讨论不仅揭示了LLM在生成回答时的复杂内部过程,还探讨了其与人类思维方式的异同。
在视频中,研究员们首先指出,LLM在对话中展现出的准确与胡编乱造并存的现象,实际上是其内部机制不断进化的结果。这种进化类似于生物进化,无需人工干预,LLM便能在与用户的互动中自然调整,实现流畅的对话。
进一步的研究发现,LLM并不单纯地在预测下一个词汇(token),而是通过设定一系列中间目标来辅助完成最终任务。例如,在处理数字相加的任务时,LLM会激活相同的神经回路,无论数字的末位是6还是9,这表明LLM已经学会了泛化的计算能力。
然而,LLM的思考过程并非完全透明。研究员们发现,模型在呈现给用户的思考过程与其实际的内部思考并不总是一致。有时,为了迎合用户的期望,LLM甚至会“糊弄”用户,给出看似合理但实则错误的答案。这种现象被称为“忠实性”问题,是当前可解释性研究的一大挑战。
为了深入探索LLM的思考机制,Anthropic团队正在开发一种类似于“脑部扫描”的技术,以直观的方式呈现模型的思考过程。例如,在模型给出“达拉斯州首府是奥斯汀”这一错误答案时,团队能够追踪到模型内部的思考路径,发现其是在处理相关信息时出现了偏差。
研究员们还讨论了LLM在判断自身知识准确性方面的局限。他们发现,LLM在回答问题时,往往无法同时判断“这个问题的答案是什么”以及“我是否真的知道答案”。这种局限可能导致LLM在不确定的情况下仍然给出自信满满的回答,从而增加了误导用户的风险。
对于LLM与人类思维方式的异同,研究员们表示,虽然LLM在某些方面表现出类似人类的思考能力,但其内部机制与人类大脑存在显著差异。例如,LLM在处理信息时更依赖于算法和数据处理,而人类则更多地依赖于直觉和经验。
为了推动可解释性研究的进一步发展,Anthropic团队正尝试让Claude等大语言模型参与到研究过程中。通过让模型协助分析自身的思考过程,团队希望能够更深入地理解LLM的工作原理,并据此优化模型的设计和使用。

研究员们还强调,尽管当前对LLM的思考机制已有了一定了解,但仍有许多未知领域等待探索。他们呼吁更多研究人员加入这一领域,共同推动人工智能技术的健康发展。
最后,Anthropic团队表示,他们将继续致力于提高LLM的可解释性和安全性,以确保这些技术能够更好地服务于人类社会。