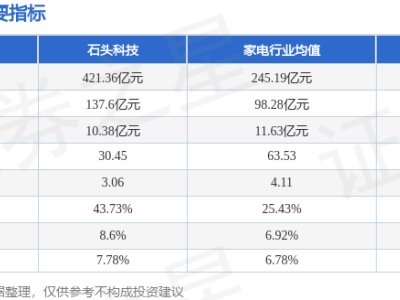
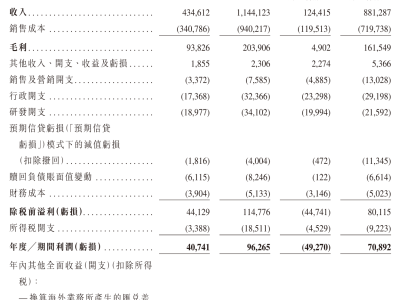
近期,科技巨头苹果公司卷入了一场关于人工智能训练数据版权争议的法律纠纷。两位作家格雷迪·亨德里克斯与詹妮弗·罗伯逊联合向法院提起诉讼,指控苹果在开发其“OpenELM”大型语言模型时,未经授权使用了他们享有版权保护的书籍内容。
根据诉讼文件,原告方指出苹果公司通过非法复制受版权保护的作品来训练人工智能系统,且在整个过程中未获得版权所有者的许可,也未提供任何形式的补偿。这一行为被认为严重侵犯了创作者的知识产权,并引发了关于人工智能时代数据使用合法性的广泛讨论。
值得注意的是,这并非人工智能领域首次因数据版权问题引发法律争议。此前,人工智能初创公司Anthropic已就类似指控达成和解,同意支付高达15亿美元的赔偿金。与此同时,微软、meta和OpenAI等行业领军企业也面临类似诉讼,显示出科技公司在利用海量数据训练人工智能模型时面临的法律风险。
诉讼文件特别提到,苹果公司被指控使用的盗版书籍涉及原告的多部作品,这些内容被整合进“OpenELM”模型的训练数据中。原告律师强调,此类行为不仅损害了创作者的经济利益,也对文化创作生态造成了负面影响。
截至目前,苹果公司尚未对此次诉讼作出正式回应,原告方律师也拒绝了媒体的置评请求。随着案件进入法律程序,其结果或将对人工智能行业的数据使用规范产生深远影响,同时也为科技公司与内容创作者之间的权益平衡提供了新的思考角度。