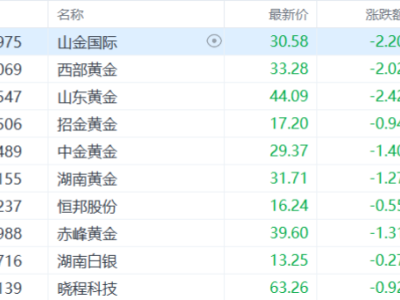
开源项目文档显示,该系统包含三个核心模块:数据采集引擎、语义分析矩阵和结果可视化界面。开发者特别优化了长文本处理能力,使模型能够准确捕捉八年前的网络语境特征。在技术实现层面,研究团队采用了分层评分机制,先通过关键词过滤初筛,再运用深度学习模型进行多维评估,最终生成包含20余项指标的评估报告。
实验配套发布的交互式网页应用,允许用户自定义筛选条件查看历史评论。系统支持按时间轴追踪特定话题的演变轨迹,也能对比不同年份的言论风格差异。开发者透露,后续计划扩展数据集覆盖范围,并增加多语言支持功能。目前该项目已收到来自学术界和产业界的数百条改进建议。