一场由国际顶尖学术机构联合开展的研究,将人工智能领域的技术竞赛推向了新高度。由香港中文大学、新加坡国立大学及牛津大学等团队主导的最新实验显示,当前最先进的AI视频生成技术已能产出以假乱真的内容,即便是专业检测系统也难以分辨,人类专家的判断准确率亦出现显著下滑。这项发表于学术平台的研究(编号arXiv:2512.13281v1),通过构建全新测试体系,揭示了AI内容生成与检测技术间的激烈博弈。
研究团队选择ASMR视频作为核心测试对象,源于这类内容对真实感的极致追求。从切菜声到水流声,从布料摩擦到工具敲击,ASMR视频通过精细的感官刺激营造沉浸体验,任何细微的不协调都会破坏整体效果。为全面评估技术能力,研究者搭建了名为"Video Reality Test"的对抗平台,采用149个高质量真实ASMR视频作为基准样本,涵盖从简单切割到复杂多步骤操作、从室内静物到户外场景的多元类型。在该体系中,AI生成模型扮演"创作者"角色,检测模型则化身"审查员",通过动态博弈模拟真实场景中的攻防对抗。
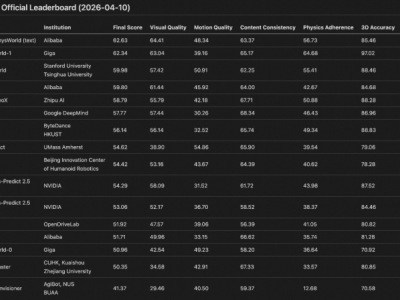
实验结果引发行业震动:谷歌开发的Veo3.1-Fast模型生成的假视频,使顶尖检测系统Gemini 2.5-Pro的识别准确率骤降至56%,近乎随机猜测水平。尽管人类专家仍保持81.25%的平均准确率,但近五分之一的误判率表明,普通用户面临更高被误导风险。更值得关注的是,开源模型如HunyuanVideo和Wan2.2-A14B的表现同样惊人,分别仅有14.77%和16.10%的生成视频被识破,显示技术门槛正快速降低。
音频线索成为破解假视频的关键突破口。研究发现,结合画面与声音分析可使检测准确率提升5个百分点。当前AI在声音生成方面仍存明显短板,例如Sora2模型常出现突兀人声,与真实ASMR视频的连续环境音效形成鲜明对比。即便表现最优的Veo3.1-Fast,其生成视频在加入音频分析后,被识破概率仍从12.54%升至15.05%,印证了多模态检测的必要性。
检测系统对水印的过度依赖暴露出致命弱点。实验显示,当移除Sora2视频的标识水印后,GPT-5和Gemini-2.5系列模型的准确率从超95%暴跌至50%左右。这种"表面化"判断模式与GPT-4o系列形成鲜明对比,后者在水印有无情况下表现稳定,显示真正的内容分析能力才是核心。研究团队指出,这种技术漏洞可能被恶意使用者利用,通过伪造水印轻易绕过审查。
检测系统的"乐观偏见"问题同样引人深思。由于互联网真实视频占比远超生成内容,多数模型形成"默认真实"的判断倾向。实验中,Qwen2.5-VL-7B模型将所有高质量生成视频误判为真实,而表现较好的模型也常将71%的视频归为真实类别。这种偏差在复杂场景中尤为明显,当视频包含多步骤操作和多样化材质时,检测准确率显著提升,揭示出当前技术处理复杂交互时的局限性。
人类专家在细节感知方面展现独特优势。经验丰富的审查者能捕捉光影异常、运动轨迹偏差等微妙不协调,平均准确率达89.11%。但18.75%的错误率提醒我们,人工审核成本高昂且难以大规模应用。有趣的是,当对比展示真假视频时,无论是AI系统还是人类专家的判断准确率都会显著提升,这种"偏好比较"现象为检测系统设计提供了新思路。
技术进步带来的社会影响引发深度讨论。一方面,AI视频生成降低创作门槛,为教育、娱乐等领域带来创新机遇;另一方面,检测技术滞后可能加剧虚假信息传播风险。研究特别强调ASMR视频的标杆意义——这类对真实性要求严苛的内容都能被模拟,标志着技术迈入新阶段。当虚拟与现实界限模糊,公众的信息鉴别能力面临前所未有的挑战。
针对技术发展路径,研究提出四大方向:强化多模态检测能力,整合视觉、音频、物理合理性等维度信息;提升系统深层理解力,减少对表面特征的依赖;完善对抗训练机制,通过生成模型与检测模型的持续博弈实现共同进化;建立标准化评估体系,推动行业健康发展。研究者承认当前研究存在局限性,未来需扩展至更多视频类型并持续更新测试平台,以跟上技术迭代速度。
这项跨国研究不仅展现了AI技术的惊人突破,更敲响了信息安全的警钟。在享受技术红利的同时,如何构建可信的数字环境成为亟待解决的课题。对于普通用户而言,提升媒体素养、培养批判思维,将成为应对信息洪流的关键能力。完整研究细节可通过学术编号arXiv:2512.13281v1查询获取。