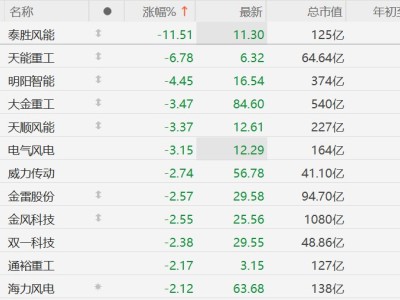
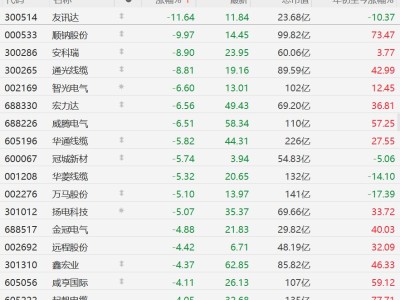
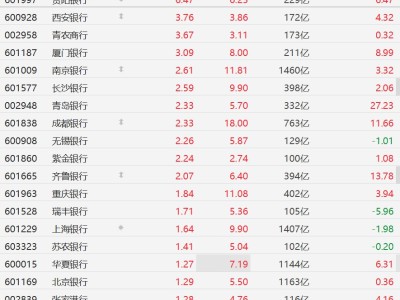
在科研领域,每年发表的学术论文数量庞大,科学家们想要紧跟最新研究进展面临巨大挑战。尽管人工智能系统在快速整合海量信息方面潜力巨大,但普遍存在编造内容,即“产生幻觉”的问题,这严重影响了其可靠性。例如,华盛顿大学与艾伦人工智能研究所(AI2)的研究团队对OpenAI最新模型GPT - 4o进行分析后发现,该模型78%至90%的研究引用都是伪造的。而且,像ChatGPT这类通用人工智能模型,通常无法读取训练数据采集完成后发表的学术论文。
为了解决这些问题,华盛顿大学与艾伦人工智能研究所的团队研发了一款名为OpenScholar的开源人工智能模型,它专为整合前沿学术研究而打造。同时,团队还构建了首个跨领域大型评测基准,用于评估模型整合与引用学术研究的能力。测试结果表明,OpenScholar的引用准确率与人类专家相当。在16位科学家进行的盲评中,51%的情况下他们更偏爱OpenScholar生成的内容,而非领域专家撰写的答复。
研究人员在完成模型训练后,为OpenScholar搭建了一个包含4500万篇学术论文的检索库,让模型的答复能够依托成熟的科研成果。团队采用检索增强生成技术,使模型在训练完成后仍可以检索新文献、整合内容并规范引用。该研究的第一作者、艾伦人工智能研究所研究科学家浅井朱里(在华盛顿大学艾伦学院读博士期间完成此项研究)介绍,研发初期,他们尝试结合谷歌搜索数据训练人工智能模型,但发现模型单独使用这类数据效果不佳,可能会出现引用关联性极低的论文、仅单篇引用,甚至随意抓取博客内容等问题。意识到必须让模型依托学术论文开展工作后,他们优化了系统灵活性,使其能通过检索结果整合最新研究成果。
为验证系统性能,团队搭建了ScholarQABench学术搜索评测基准,专门用于测评科研类人工智能系统。团队收集了3000条检索查询,以及计算机科学、物理学、生物医学、神经科学领域专家撰写的250篇长文答复。
研究团队将OpenScholar与GPT - 4o、meta旗下两款顶尖人工智能模型进行对比,通过ScholarQABench从准确性、撰写质量、内容相关性等维度自动评测模型答复。结果显示,OpenScholar的表现优于所有参测模型。在邀请16位科学家对各模型与人类专家的答复进行盲评对比时发现,51%的情况下科学家更认可OpenScholar的答复,而非人类专家;若将OpenScholar的引用机制与工作流和大模型GPT - 4o结合,科学家对人工智能答复的偏好率升至70%;仅使用GPT - 4o原生生成内容时,科学家偏好率仅为32%。
该研究的通讯作者汉娜内·哈吉希里齐,同时也是华盛顿大学保罗·G·艾伦计算机科学与工程学院副教授、艾伦人工智能研究所高级总监,她表示:“我们上线演示版本后,很快就收到了远超预期的海量访问请求。梳理用户反馈后发现,同行和其他科研人员都在积极使用OpenScholar,这充分说明科研领域迫切需要这类开源、透明的学术研究整合系统。”
浅井朱里还提到,科学家每天要面对海量新发论文,根本无法全部跟进,而现有人工智能系统并非针对科研人员的专属需求设计。目前已有大量科研人员使用OpenScholar,得益于其开源属性,业内同行已在本研究基础上迭代优化,进一步提升了模型效果。团队正在研发迭代模型DR Tulu,该模型基于OpenScholar的技术成果,可实现多步骤检索与信息聚合,生成更全面的研究答复。