在金融科技领域,随着“人工智能+”战略的深入实施,大型模型技术正逐步在金融行业中扎根生长。为了衡量这些大型模型在金融场景下的专业性和可靠性,上海财经大学近期对其金融领域大模型评估基准进行了升级,推出了Fineval 6.0版本,并首次引入了金融严谨性等新的评估维度,同时发布了首份详细的评测报告。
作为国内金融领域大模型测评的先行者,上海财经大学早在2024年就参与了《金融大模型应用测评指南》的制定工作,该指南是全国首个聚焦于金融业务能力的团体标准。此次升级,Fineval 6.0基于广泛的行业调研和投资者反馈,特别强化了金融严谨性的评测样本,从金融学术知识、行业理解、严谨性测试、安全认知以及智能体应用等多个方面,对大型模型在复杂金融场景中的实际应用能力进行了全面评估。
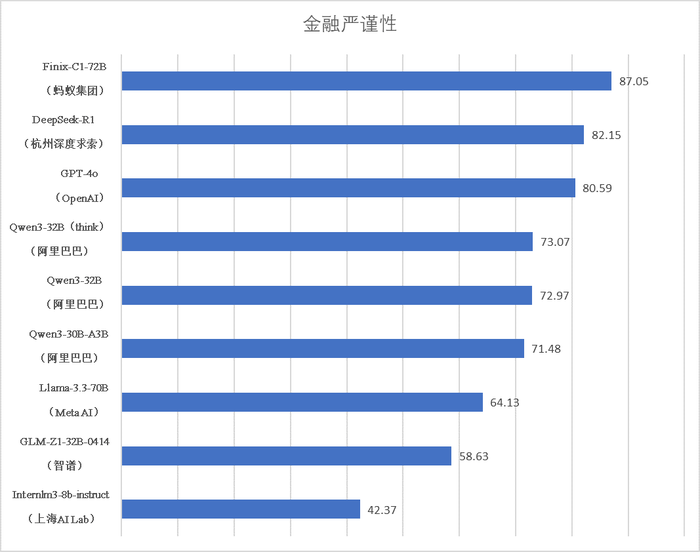
在Fineval 6.0的评测中,国内外共9款具有代表性的大型模型接受了考验,包括DeepSeek-R1、GPT-4等通用基础模型,以及专注于金融领域的垂直模型。评测结果显示,虽然所有模型在金融学术知识方面均表现出色,但在金融严谨性和行业理解等关键能力上,各模型之间的差异显著。蚂蚁集团旗下的理财AI“蚂小财”凭借其强大的模型底座,在金融严谨性等多个维度上脱颖而出,总分超越了多款通用大模型。
特别是金融严谨性这一维度,行业平均得分仅为70.27分,而“蚂小财”则以高出均值17分的优异成绩遥遥领先。作为蚂蚁集团旗下的AI理财助手,“蚂小财”不仅连接了蚂蚁财富平台上的200多家基金公司、券商和财经媒体的内容与服务,还在通用大模型的基础上,构建了金融智能增强技术体系,显著提升了金融场景下的专业功能和交互体验。
上海财经大学教授张立文作为测评团队的负责人指出,金融领域是AI技术应用的重要场景之一,对AI的专业性和严谨性提出了更高要求。近年来,国内AI在金融领域的应用水平不断提升,逐渐从“博学多才”向“专业审慎”转变,为下一阶段的大规模应用奠定了坚实基础。这些积极的探索不仅有助于提升我国在国际AI产业竞争中的地位,还将为数字金融和普惠金融的发展开辟新篇章。