在人工智能的浩瀚宇宙中,计算机视觉领域再度迎来了一颗璀璨新星。meta公司近期宣布并开源了其最新的视觉基础模型——DINOv3,这一成果不仅标志着自监督学习技术在计算机视觉任务中的重大突破,也为图像理解开启了新的篇章。
自监督学习,这一无需人工标注数据即可自主学习的范式,近年来已成为机器学习领域的热门话题。它推动了大型语言模型的崛起,并在计算机视觉领域逐渐崭露头角。DINOv3正是在这一背景下应运而生,它继承了前代DINO和DINOv2的优秀基因,并在此基础上实现了质的飞跃。
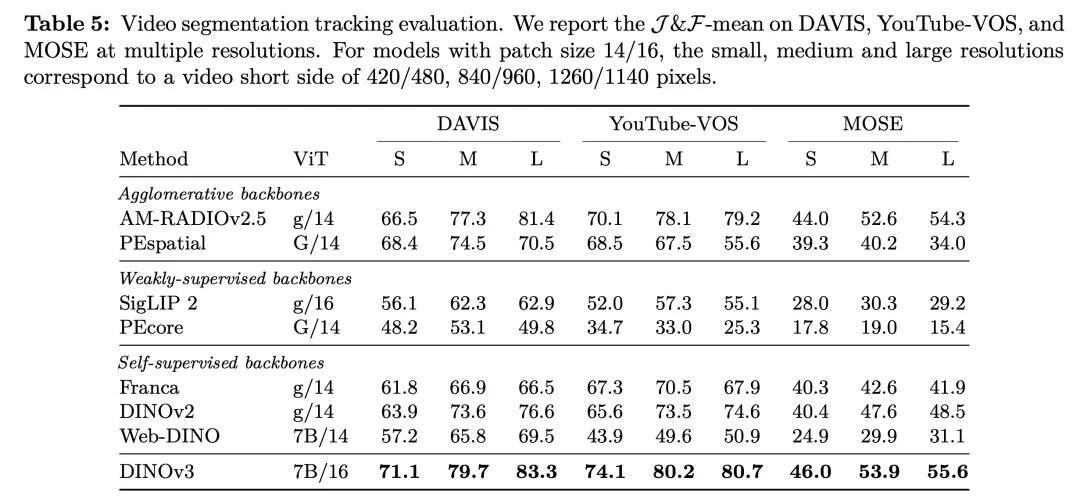
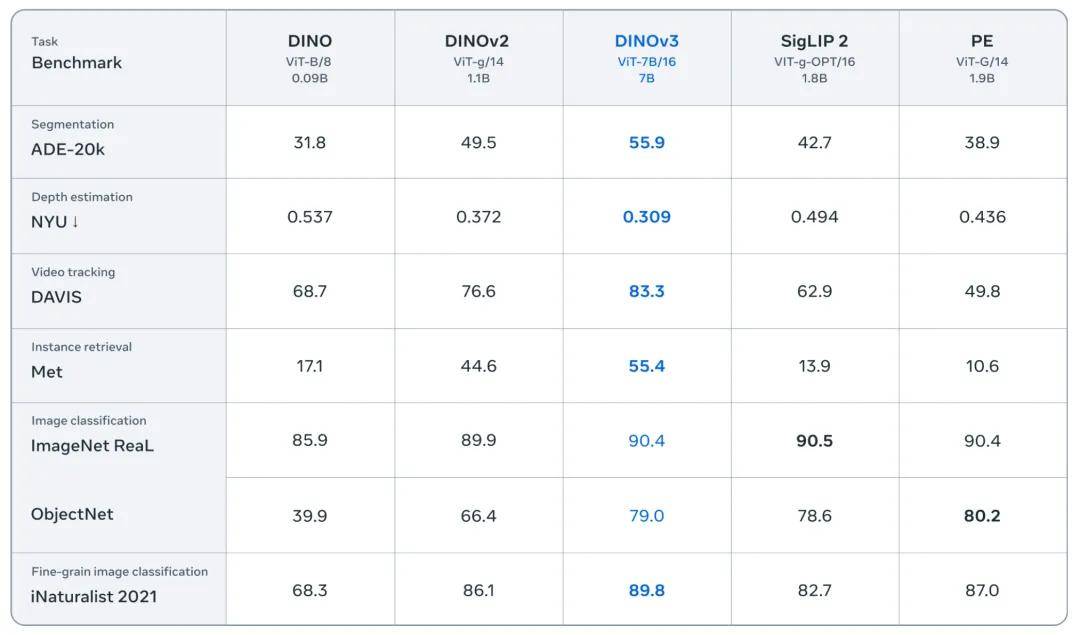
DINOv3的核心优势在于其创新的自监督学习技术和庞大的训练数据集。该模型采用了突破性的DINO算法,无需任何元数据输入,仅需少量计算资源即可产出卓越的视觉基础模型。通过训练17亿张图像,DINOv3的模型参数规模达到了惊人的70亿,使其在多个下游任务中展现出了非凡的性能。
尤为DINOv3在密集预测任务中取得了显著领先。无论是目标检测、语义分割还是相对深度估计,DINOv3都展现出了对场景布局与物理结构的深刻理解能力。这一突破得益于其引入的一系列新改进,如Gram Anchoring策略和旋转位置编码RoPE,这些技术有效缓解了密集特征的坍缩问题,并使得模型能够天然适应不同分辨率的输入。
meta公司表示,DINOv3不仅在技术上实现了突破,更在实际应用中展现出了巨大潜力。该模型已被用于卫星图像分析、环境监测、城市规划以及灾害响应等多个领域。例如,在世界资源研究所(WRI)的项目中,DINOv3通过分析卫星图像,成功检测了森林损失和土地利用变化,为气候金融支付流程提供了精确验证,加速了资金发放,特别支持了小型本地组织。
DINOv3的通用性和高效性也使其成为边缘应用场景的理想选择。由于无需对骨干网络进行微调,单次前向传播即可同时服务多个任务,从而显著降低了推理成本。这一点对于需要同时执行多项视觉预测任务的场景尤为重要。
为了满足不同推理计算需求,meta公司还构建了一个涵盖不同规模的模型家族。通过将大型模型进行蒸馏,得到了一系列更小但性能依旧出色的模型变体,如ViT-B和ViT-L等。这些模型不仅保持了DINOv3的卓越性能,还更加易于部署和应用。
DINOv3的发布和开源,无疑为计算机视觉领域注入了新的活力。它不仅展示了自监督学习的强大潜力,更为研究人员和开发者提供了一个全新的工具平台。随着DINOv3在更多领域的应用和推广,我们有理由相信,它将为人工智能的发展开启更加广阔的前景。