
在人工智能领域,一项革命性的突破正悄然改变着我们对世界的认知与模拟能力。谷歌DeepMind最新推出的Genie 3,被誉为迄今为止最先进的世界模型之一,它仅凭文本输入,便能实时构建出高度互动、内在逻辑严密的世界。
Genie 3不仅是DeepMind技术积累的集大成者,更是向通用人工智能(AGI)及具身智能体迈出的关键步伐。近日,DeepMind的研究科学家Jack Parker-Holder与研究总监Shlomi Fruchter,在a16z的访谈中,深入探讨了Genie 3的构建原理及其未来展望,引发了业界的广泛关注。

访谈中,Jack与Shlomi分享了Genie 3背后的故事。该项目是Veo 2与Genie 2两大DeepMind项目的结晶,旨在探索实时、互动世界模型的无限可能。他们强调,尽管应用前景广阔,但研究的核心并非追求具体应用,而是让模型在用户的探索中自然展现出其潜力。
Genie 3的一大亮点在于其卓越的空间记忆能力,能够保留长达一分钟的场景细节。物理规律在模型中自然生成,并随着训练数据的增加而不断完善。目前,尚无一个模型能同时具备Veo 3与Genie 3的全部功能,这使得Genie 3在人工智能领域独树一帜。
如果说大型语言模型的图像编辑功能是“言出法随”的魔法,那么Genie 3则以其独特的动态世界生成能力,为用户带来了前所未有的体验。用户只需输入简单的文本提示,Genie 3便能以每秒24帧、720p分辨率的速度,实时生成一个可供探索的虚拟世界。
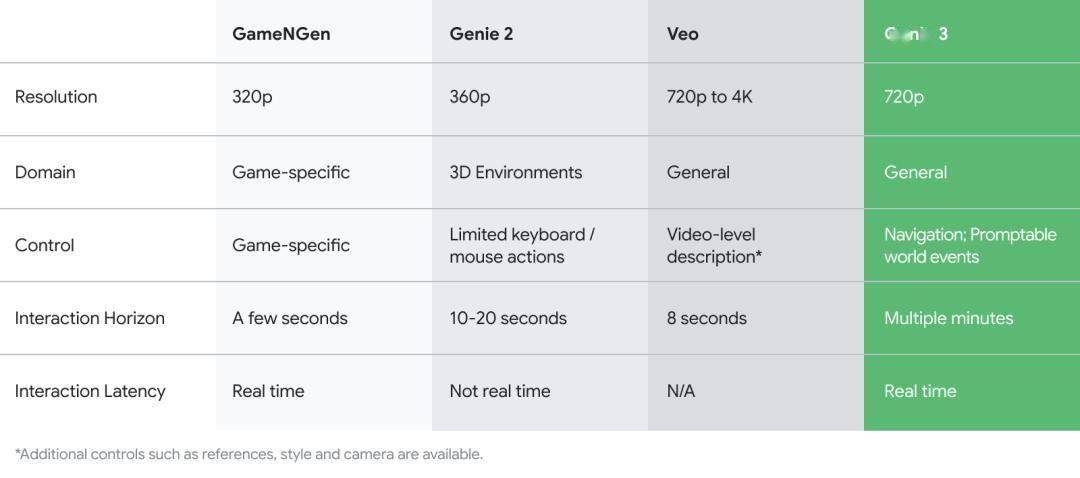
十多年来,DeepMind一直致力于模拟环境的研究,而Genie 3无疑是这一领域的巅峰之作。它不仅在视频生成时长、世界一致性、内容多样性等方面取得了显著突破,更引入了“特殊记忆”这一创新特性。例如,在模型中,一个角色在墙上刷漆后移动至另一侧,再返回时,之前的漆痕依然清晰可见,这种高度一致性的表现令人叹为观止。
Genie 3的“记忆”能力相较于其前身有了质的飞跃。在设定目标时,DeepMind团队不仅追求超过一分钟的记忆时长,还支持实时生成与分辨率的提升,这些看似矛盾的目标在Genie 3中得到了完美融合。团队在设计上摒弃了显式表示法,转而采用逐帧生成的方式,以增强模型的泛化能力与适应多样世界的能力。
随着模型的规模扩大,Genie 3涌现出了一系列令人惊讶的行为。角色会根据情境做出符合人类直觉的动作,如靠近门时尝试打开,对语言的理解也更加深入,生成的内容愈发真实自然。从Genie 2到Genie 3,模型在模拟现实世界的能力上实现了巨大飞跃,物理效果与光照变化均达到了以假乱真的程度。
Genie 3在“地形多样性”方面也表现出色。模型能够准确理解不同地形上的行走、滑雪、游泳等动作及其物理反馈,这些行为都是模型通过丰富的训练数据自学而成的。例如,角色在滑雪时会根据坡度调整速度,下水后会开始游泳或溅起水花,这些自然流畅的动作令人仿佛置身于真实世界之中。
未来,DeepMind团队将继续致力于提升模型的真实感与交互性,为机器人学习等领域提供更广阔的虚拟场景。他们相信,世界模型将是智能体走向现实世界的最快路径,而Genie 3已经在这条路上迈出了坚实的一步。至于人类是否生活在某种模拟中,这一哲学问题或许只能留给未来去解答了。











