在人工智能领域,模型推理被视为连接理论创新与实际应用的纽带,其重要性不言而喻。清华大学郑纬民教授指出,尽管更大的数据量、模型规模以及更长的上下文窗口能够推动人工智能效率的提升,但伴随而来的是沉重的推理负载与庞大的存储需求。特别是模型推理过程中产生的KV Cache,对于连续长文本对话而言,其存储与快速访问成为制约AI应用落地的一大瓶颈。
郑教授比喻道,高效的模型推理如同流畅的对话,而KV Cache则是支撑这一流畅性的关键记忆。然而,当前的GPU服务器显存有限,难以容纳日益增长的KV Cache,这导致要么牺牲响应速度进行重复计算,要么投入巨资扩大存储规模。如何在保证响应速度的同时,有效控制成本,成为亟待解决的问题。
以漫画创作为例,一位名叫小刘的漫画家在面对连载压力时,遇到了与AI推理类似的困境。他需要回顾并参考大量的过往情节来推进新话的创作,但随着连载的增加,“漫画故事墙”上的便利贴逐渐饱和,无法再容纳更多信息。为了克服这一难题,小刘寻求了专业漫画家小李(Inspur Data的化身)的帮助。
小李提出了三项创新策略,首先,他引入了一个名为AS3000G7的“剧情档案柜”,用于存储“漫画故事墙”放不下的便利贴。这个档案柜不仅扩大了存储容量,还能通过智能技术快速响应小刘对剧情信息的需求,有效缓解了存储压力。

其次,小李为小刘配备了画稿调度员小张,负责高效管理“漫画故事墙”与“剧情档案柜”之间的信息流动。小张通过智能多路径优化和动态缓存管理,确保了热门剧情信息的快速访问,同时合理安排了档案柜的补全与清理工作,使得整个信息调度过程既高效又流畅。
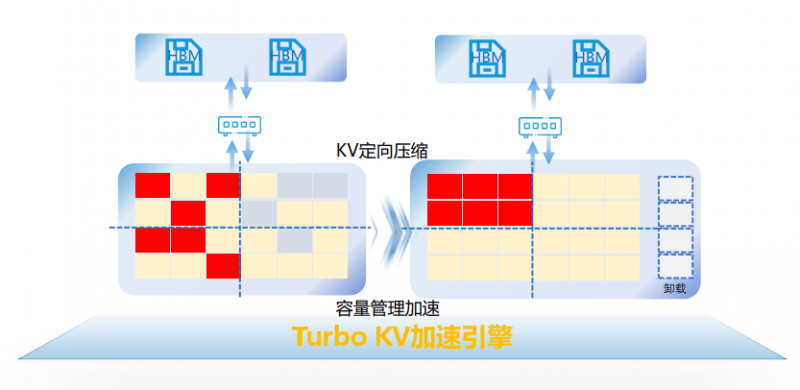
最后,小李还推荐了一位档案管理员老赵,他精通空间利用与管理。老赵通过定向压缩和容量管理加速算法,最大限度地提高了档案柜的存储效率,确保了空间的有效利用,同时避免了无效信息的堆积。
将这些策略应用于AI模型推理中,AS3000G7推理加速存储系统通过硬件池化技术整合了多种存储资源,实现了存储容量的巨大扩展,有效缓解了GPU显存的瓶颈问题。智能调度技术则加快了外置存储与GPU显存之间的数据传输速度,确保了连续长文本对话的快速响应。而精细管理技术则进一步提升了存储空间的利用率,降低了推理成本。
在小李的帮助下,小刘的漫画创作变得前所未有的顺畅。无论是从“漫画故事墙”直接取用信息,还是从“剧情档案柜”中调取历史情节,速度都显著提升。这不仅极大地提高了他的创作效率,还降低了成本,使他能够同时推进多部连载作品,从容应对读者的催更压力。