近日,人工智能领域迎来了一则令人瞩目的消息:DeepSeek官方悄然宣布,其最新版本的模型DeepSeek-V3.1已正式发布。这一消息迅速在网络上发酵,仅发布一个小时,就在某平台上获得了高达26万的浏览热度。
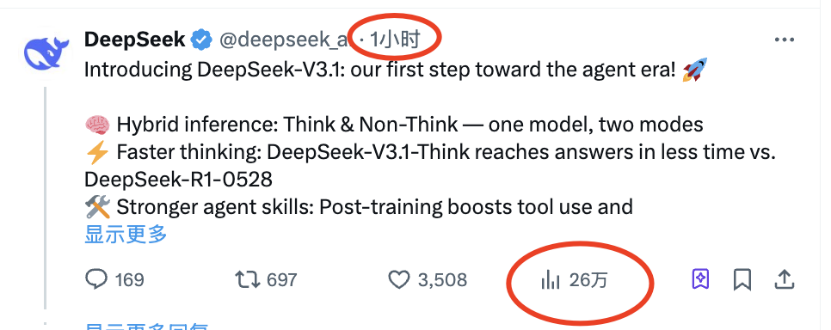
据DeepSeek官方介绍,DeepSeek-V3.1是一款集思考与非思考模式于一体的混合型模型。用户可以根据实际需求,灵活切换这两种模式,从而在效率和能力之间找到最佳平衡点。这一创新设计,无疑为用户带来了更加便捷和高效的使用体验。
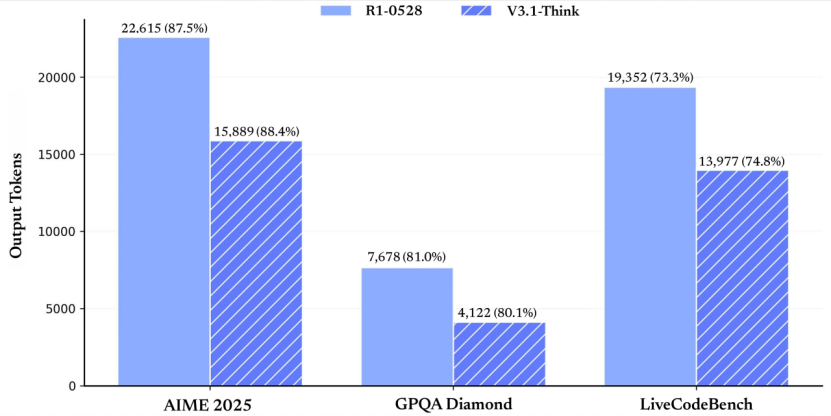
DeepSeek-V3.1在多个方面均取得了显著进步。得益于深度优化的训练策略和大规模长文档扩展,该模型在推理速度、工具调用智能、代码和数学任务处理等方面均表现出色。据官方公布的测试结果显示,DeepSeek-V3.1在AIME 2025(美国数学邀请赛2025版)、GPQA Diamond(高难度研究生级知识问答数据集的Diamond子集)以及LiveCodeBench(实时编码基准)等多个基准测试中的得分均优于老模型R1-0528。
尤为DeepSeek-V3.1在输出tokens数量上实现了大幅减少,同时保持了相似或略高的准确率。这意味着该模型在计算资源优化方面取得了显著优势,为用户节省了宝贵的计算资源。
在软件工程和Agent任务基准上,DeepSeek-V3.1同样表现出色。在SWE-Bench Verified测试中,该模型得分66.0%,远高于V3-0324和R1-0528。在多语言版本的SWE-Bench测试中,DeepSeek-V3.1也取得了54.5%的高分,显示出其在多语言支持方面的显著进步。而在Terminal-Bench测试中,该模型得分31.3%,同样优于前代模型,展现了其在Agent框架下效率的大幅提升。
DeepSeek-V3.1的这次更新,不仅增强了模型的智能体能力,还在搜索Agent、长上下文理解、事实问答和工具使用等领域展现了强劲性能。基于MoE架构的DeepSeek-V3.1(总参数671B,激活37B)在大多数基准上均显著优于R1-0528,尤其在工具使用和事实QA中领先,为构建AI Agent应用提供了有力支持。
在Huggingface平台上,DeepSeek释放出了更详细的评估结果。结果显示,DeepSeek-V3.1在常规推理和知识问答任务上的整体表现稳定提升,非思考和思考模式下的分数均高于V3旧版,基本接近行业顶尖大模型水平。例如,在HLE(Humanity’s Last Exam,搜索+Python复合推理)任务上,DeepSeek-V3.1实现了29.8%的通过率,优于自家R1-0528版,并接近GPT-5、Grok 4等国际一线大模型。
除了性能上的显著提升,DeepSeek-V3.1的价格也备受关注。此次发布的新模型在价格上同样给出了诚意满满的方案。输入定价分为缓存命中和缓存未命中两种情况,分别为0.07美元/百万tokens和0.56美元/百万tokens。而输出定价则为1.68美元/百万tokens。这一价格方案无疑为用户提供了更加经济实惠的选择。
DeepSeek-V3.1还首次实现了对Anthropic API的原生兼容。这意味着用户可以将DeepSeek无缝集成到现有系统中,像调用Claude或Anthropic生态的模型一样使用DeepSeek-V3.1提供的推理和对话能力。这一兼容性无疑为开发者带来了更多便利和可能性。
DeepSeek-V3.1的发布,无疑在人工智能领域掀起了一股新的热潮。尽管它并非“无敌”的存在,但其明确的侧重点和显著优势,无疑为用户和开发者带来了新的选择和机遇。而DeepSeek这种低调、高效、开发者友好的发布方式,也赢得了广泛好评和赞誉。