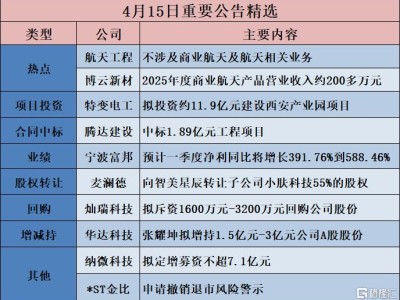
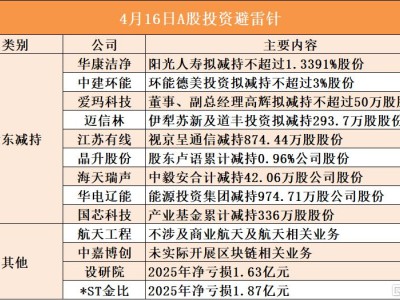
近日,DeepSeek正式推出了其备受瞩目的V3.1版本,此次更新不仅将上下文长度扩展至128k,更在模型架构上实现了重大突破。V3.1采用了创新的混合推理架构,集思考模式与非思考模式于一体,用户通过API调用时,将统一识别为V3标识,这一变革大大简化了部署流程,提升了算力使用效率。
在性能提升方面,DeepSeek V3.1的编程能力实现了质的飞跃。据Aider编程基准测试结果显示,V3.1以71.6%的高分傲视群雄,不仅超越了前任R1版本,甚至超过了闭源模型Claude 4 Opus。在SVGBench测试中,V3.1紧随GPT-4.1-mini之后,远超前代R1的表现。在多任务语言理解测试MMLU中,V3.1也取得了88.5%的优异成绩,与GPT-5不相伯仲。然而,在研究生级别问答GPQA和软件工程SWE-Bench等领域,V3.1与GPT-5之间仍存在一定的差距。
DeepSeek V3.1在成本效益方面也取得了显著进展。完成一次完整的编程任务,V3.1的成本仅为约1.01美元,相较于Claude 4 Opus,成本降低了68倍之多。官方公布的新价格表显示,输入价格为0.5元/百万tokens(缓存命中)和4元/百万tokens(缓存未命中),输出价格则为12元/百万tokens,该价格策略将于2025年9月6日起正式生效。这一成本的大幅下降,主要得益于思维链压缩训练技术的运用,有效减少了无意义的输出。
在智能体能力方面,V3.1同样表现出色。经过后训练优化,新模型在工具使用和智能体任务中展现出了卓越的性能。在SWE-bench Verified基准测试中,V3.1以66.0分的成绩遥遥领先前代。而在Terminal-Bench测试中,V3.1更是以31.3分的成绩,达到了前代五倍以上的水平。V3.1在网页浏览和工具调用能力上也得到了全面提升。
然而,V3.1的“模型融合”策略却引发了社区的广泛争议。部分用户反映,新版本中幻觉现象严重,且出现了中英夹杂的问题。同时,在面对复杂问题时,V3.1似乎更倾向于“能省则省”,这在一定程度上影响了其处理复杂任务的能力。DeepSeek激进的更新策略也让商业API用户感到不满。新模型直接替代了旧模型,且未提供旧版本的API接口,这导致线上生产业务的API可能在没有预警的情况下被更改,给商业应用的稳定性带来了严重影响。