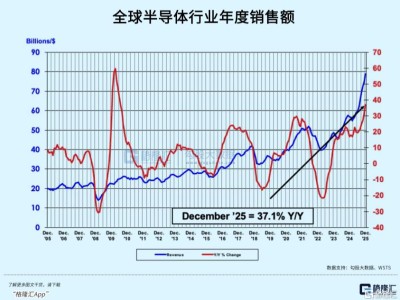
近期,芯片与AI算力领域迎来了显著的增长动力,具体表现为芯片指数(884160.WI)与AI算力指数(8841678.WI)在一个月内分别飙升了19.5%和22.47%。这一趋势背后,是AI技术的蓬勃发展以及大模型对算力需求的急剧增加,促使国产替代步伐加快,供应链多元化策略日益成熟。
在消息面上,DeepSeek公司近期发布的DeepSeek-V3.1版本,声称是向Agent(智能体)时代迈进的关键一步。该版本采用了UE8M0 FP8 Scale参数精度,专为即将面世的下一代国产芯片设计。这一举措不仅精准捕捉到了行业对于高效低功耗计算的迫切需求,还掀起了一股低精度计算的热潮,为国产算力领域注入了新的活力。
事实上,FP8作为一种8位浮点数格式,并非新鲜事物。早在2022年,英伟达就在GTC大会上预告了FP8将支持其Hopper架构的H100 GPU。然而,由于低精度计算涉及芯片、软件、模型、标准等多个环节,当时包括CUDA、PyTorch、TensorFlow在内的主流软件栈平台都尚未原生支持FP8算子。随着GPT-4与Llama-2等大模型的验证,FP16的适用性得到确认,FP8才开始逐渐被行业接纳并进行测试。
2023年,由meta、微软、谷歌、阿里等巨头共同成立的开放计算项目OCP发布了《MX规范》第一版本,通过“块缩放”技术将FP8包装为可大规模落地的MXFP8。随后,框架厂商开始逐步添加FP8支持代码,AI投资的重点也从单纯追求GPU数量转向了算力效率。到了2024年,随着万卡集群的出现和推理需求的爆发,成本、功耗、显存成为更为核心的问题,FP8因其省显存、省电费、速度快等优势,逐渐受到更多厂商的关注和布局。

DeepSeek通过V3模型成功运行MXFP8,标志着MXFP8在复杂AI训练任务中的高效性得到了验证,吸引了众多AI开发者、研究机构及企业的目光。从MXFP8到UE8M0 FP8,行业内编码方式、动态范围、硬件处理、应用场景和生态发展均实现了升级迭代,更加聚焦于大语言模型训练等场景,展现出低精度计算在提升效率上的巨大潜力。
在二级市场上,多家芯片公司与券商机构借DeepSeek的东风,密集披露了FP8布局与解读。这背后既有技术因素的影响,更是国产AI芯片产业争夺产业主导权的趋势所驱动。据财通证券研报预测,2025年第二季度国产芯片市占率将提升至38.7%。同时,工信部印发的《算力互联互通行动计划》也提出了到2028年基本实现全国公共算力标准化互联的目标。
行业方面,随着OpenAI开源首个原生态支持FP4格式的GPT-OSS系列大模型,AI领域已正式进入低精度计算时代。大模型需要越来越多的硬件来支撑训练和推理的计算,而模型低精度量化则能有效应对计算量大、储存不足和数据传输慢等问题。多家国产算力厂商表示,FP8的混合精度训练框架将推动算力厂商调整技术路线,多精度混合架构能够显著提升训练效率。
然而,低精度计算并非没有边界。有专家指出,当精度过低时,数据可能会因失真而无法承载大模型所需的信息。因此,在低精度数据主要应用于模型推理的同时,大模型的训练或微调过程中仍需使用更高精度的数制。FP8的落地还需要芯片、框架、算子全链路适配,国产算力厂商正通过定制化方案突破生态壁垒。

尽管存在挑战,但低精度计算的趋势已不可逆转。随着低精度训练方法的成熟和更多芯片在硬件上对低比特格式的支持,大模型的训练时间将大幅缩短,催生更大、能力更强的模型。同时,低精度计算还能显著提升大语言模型等文本生成任务的效率,并改善多模态领域的生成效率。国产算力产业链已完成“融资—研发—场景落地”的正向循环,正稳步走出一条独立于海外生态的可持续路径。