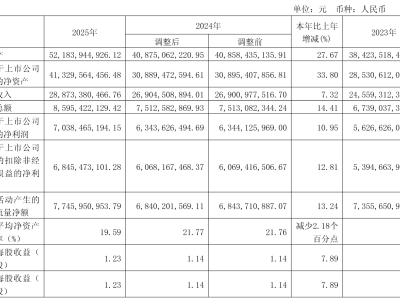
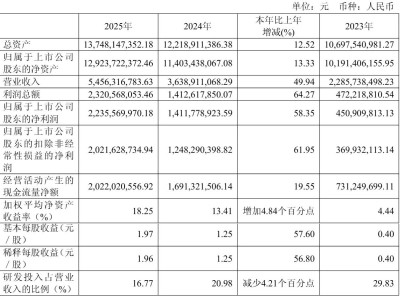
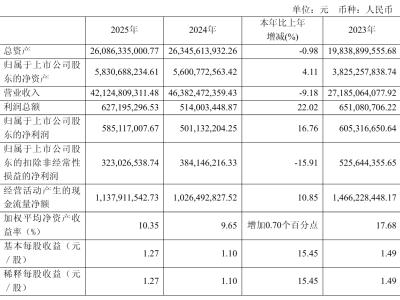
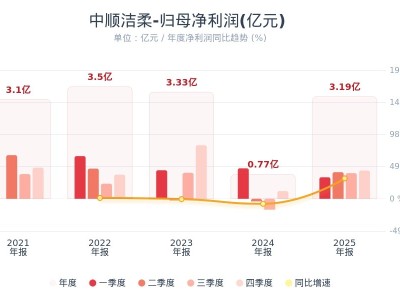
近日,谷歌DeepMind团队发布了一项突破性研究,该研究由Michael Tschannen和Xiaohua Zhai领导,介绍了一种名为SigLIP 2的新一代多语言视觉-语言编码器。这项研究通过arXiv:2502.14786v1论文公开,展示了AI系统在理解多语言图像内容方面的非凡能力。
SigLIP 2的发布标志着AI技术的一大进步,它不仅能够理解英语图片,还能准确解读包括中文、日语、阿拉伯语在内的36种不同语言的图像内容。这一成就使AI如同拥有了一双“超级眼睛”,能够跨越语言障碍,实现全球图像内容的无缝理解。
人类理解图片的方式是大脑将视觉信息与语言概念快速连接。例如,看到猫的照片,人们会立刻想到“猫”这个词,并能用不同语言描述猫的特征。SigLIP 2通过模仿这一过程,使AI也具备了跨语言“看图说话”的能力,且表现卓越。
研究团队采用了分阶段的训练方法,逐步提升AI的视觉和语言理解能力。首先,他们延续了SigLIP的基础架构,为AI提供了基本的视觉理解能力。随后,通过加入“看图写话”训练和“自我学习”机制,AI学会了为图片写标题,并能根据描述准确找到图片中的物体位置。
SigLIP 2最令人惊叹的能力之一是精准的视觉定位。它能够像经验丰富的向导一样,准确指出图片中特定物体的位置。这一能力的实现得益于研究团队开发的“并行预测”训练方法和自动标注系统,使AI能够从局部信息推断整体内容,大大提升了理解精度。
为了满足不同尺寸和比例图片的处理需求,SigLIP 2还推出了名为NaFlex的变体版本。NaFlex能够自动调整图片尺寸,保持原始比例,避免了传统方法中的图像扭曲问题。这一设计在处理文档图像和宽屏照片时尤为有效,显著提高了文字识别和图像处理的准确性。
针对计算资源有限但需要高性能AI的场景,研究团队开发了一套“知识传承”方法。通过智能样本选择,他们让大模型作为“导师”筛选最有价值的学习材料,指导小模型学习。这种方法使小模型在有限资源下也能达到接近大模型的性能水平。
在多语言理解能力方面,SigLIP 2在Crossmodal-3600数据集上取得了显著成绩,平均召回率达到了48.2%,相比原版SigLIP提升了一倍多。同时,它在保持强大英语理解能力的同时,对非西方文化的图像内容也表现出了更好的理解公平性。

SigLIP 2在复杂视觉任务上的表现同样令人瞩目。在语义分割、深度估计、表面法向量预测等任务中,它都展现出了卓越的能力。特别是在开放词汇检测和分割任务上,SigLIP 2能够识别和分割训练时从未见过的物体类别,这一成就证明了其强大的知识迁移能力。
研究团队还特别关注了AI系统的文化敏感性和公平性。通过去偏见技术处理训练数据,SigLIP 2在表示偏见方面取得了显著改善,减少了性别、种族或文化刻板印象的影响。这一进步使AI能够更好地服务全球用户,提供公平、准确的智能服务。
SigLIP 2的成功不仅在于其技术性能的突破,更在于其多语言支持、文化公平性和应用灵活性的提升。这项研究为AI视觉理解技术的发展树立了新的标杆,预示着未来AI技术将更加智能、更加包容。
对于想要深入了解SigLIP 2的读者,建议查阅发表在arXiv上的完整论文,那里有更详尽的技术说明和实验数据。同时,普通用户也可能在各种AI应用中间接体验到这项技术,如多语言图像搜索、智能相册分类等。
Q&A
Q1:SigLIP 2相比原版SigLIP有哪些主要改进?
A:SigLIP 2加入了解码器训练、自蒸馏学习、多语言支持和数据去偏见技术,使AI在图像理解、定位和多语言能力方面都有了显著提升。
Q2:SigLIP 2如何实现多语言图像理解能力?
A:SigLIP 2通过精心设计的数据配比和去偏见技术,实现了对36种语言图像内容的公平准确理解。
Q3:普通用户如何使用SigLIP 2技术?
A:目前SigLIP 2主要通过开源形式提供给开发者使用,普通用户可以在各种AI应用中间接体验到这项技术带来的便利。