
近日,微软震撼发布了其首个开源的“原生1bit”大型语言模型——BitNet b1.58 2B4T,这一创新之举在AI界掀起了轩然大波。该模型拥有20亿参数,训练数据高达4万亿token,它通过颠覆性的方式重构了AI的计算引擎。
与传统大型语言模型(如GPT系列)依赖高精度浮点数或低精度整数不同,BitNet采用了激进的三元量化方法。模型中的每个权重只能是-1、0或+1这三个值,这一设计在训练时就确保了推理时无精度损失。这种三元量化方法,不仅极大地减少了内存占用,还使得计算过程从复杂的乘法转变为简单的加减法,从而实现了超高的计算效率。
BitNet的革命性优势主要体现在极致的效率和成本效益上。由于每个权重仅需约1.58位存储,相比16位浮点数,BitNet的内存占用降低了约10倍。这意味着,过去需要庞大数据中心支持的大型模型,未来或许能在个人电脑甚至智能手机上流畅运行。同时,计算速度的显著提升和能耗的大幅下降,使得在边缘设备上部署强大AI成为可能,响应了全球对绿色计算和可持续发展的需求。
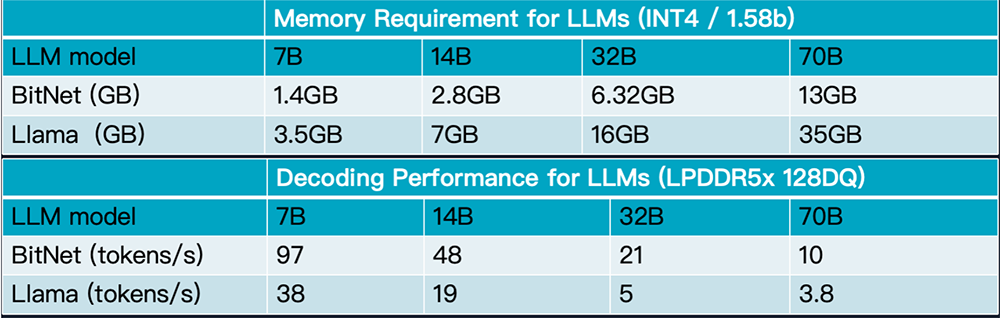
微软的研究表明,BitNet在保持高性能的同时,还打破了“模型越大且精度越高,性能才越强”的传统认知。在一定模型规模以上,BitNet的性能可以媲美甚至超过同等规模的半精度模型。这一突破性的表现,让人们对AI的未来充满了期待。
在国际上,尽管大型电子硬件公司如苹果、三星等尚未公开宣布将BitNet集成到其产品中,但相关的适配工作已经在紧锣密鼓地进行中。微软开源的bitnet.cpp框架,为BitNet在智能硬件上的高效运行提供了关键支持。该框架专为CPU设计,支持跨平台运行,特别是在Arm架构上的性能表现令人瞩目。测试数据显示,在ARM CPU上使用bitnet.cpp运行BitNet模型,速度相比传统16位浮点模型有显著提升,能耗也大幅降低。
在国内,边缘AI芯片厂商芯动力已经成功实现了微软BitNet大语言模型的本地化高效适配。其自主研发的RPP架构完美支持BitNet-b1.58-2B-4T模型推理,并在联想ThinkPad 16p Gen6这款革命性AI PC上展现出了卓越的推理能力。这一突破标志着国产AI加速技术在边缘计算领域取得了重大进展。

BitNet的应用前景广阔,特别是在与具身机器人的结合上。低精度计算与机器人硬件的深度适配,使得BitNet能够满足具身机器人对本地化部署、计算处理能力与能耗的最优化要求。从工业到消费领域,BitNet都有望实现规模化渗透,助力小型化设备实现复杂指令理解与环境交互。
BitNet还有望引爆家电、汽车和手机市场。在手机产业中,BitNet将推动“智能手机”向“AI手机”的终极跃迁,实现超级个人助理、永不掉线的实时功能以及极致个性化体验。在汽车产业中,BitNet将加速迈向真正的“智能座舱”与“自动驾驶”,提升自动驾驶的安全性与可靠性。在家电产业中,BitNet将让家电从“功能性产品”转变为“有智慧的家庭成员”,实现主动服务和无处不在的自然交互。
微软BitNet框架的发布,不仅为边缘AI的加速普及带来了新的活力,也为中国企业提供了一个在AI应用领域“换道超车”的绝佳机会。随着技术的不断成熟和相关工具链的完善,我们有理由相信,BitNet将在未来发挥更加重要的作用,推动AI技术的快速发展和广泛应用。











