人工智能领域中,大型语言模型(LLM)的“幻觉”问题始终是制约其广泛应用的核心障碍。这种看似合理却实为错误的输出,不仅让用户难以分辨信息真伪,更成为阻碍AI技术可信度提升的关键因素。OpenAI最新发布的论文《语言模型为何产生幻觉》从统计学视角切入,系统剖析了这一现象的深层机理。

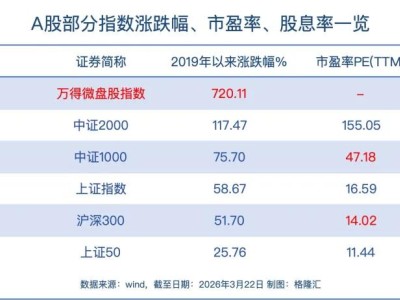
研究团队通过实验发现,当前主流的模型评估体系存在根本性缺陷。以多项选择题类比,当模型面对不确定问题时,现行评估机制更倾向于奖励“蒙题”行为——随机猜测有1/365的概率答对生日问题,而明确表示“不知道”则必然失分。这种激励机制导致模型在真实场景中频繁输出错误信息,而非坦诚承认认知局限。OpenAI以SimpleQA评估为例指出,早期o4-mini模型虽在准确率上略胜一筹,但其错误率(即幻觉发生率)显著高于后续版本,这正是“为准确率牺牲可信度”的典型表现。
论文核心发现之一,在于揭示了预训练阶段的数据特性与幻觉的关联。语言模型通过海量文本预测下一个词来学习,这种无监督学习方式缺乏“真/假”标签的校正。研究团队类比图像识别任务:若用宠物生日标记照片,无论算法多先进都无法避免错误,因为生日本质上是随机信息。同理,模型在处理低频事实(如特定人物论文标题)时,由于缺乏可预测的模式,必然产生幻觉。这与拼写错误等高频模式问题形成鲜明对比——后者随着模型规模扩大自然消失。
针对评估体系的改革方案,OpenAI提出“惩罚自信错误、奖励不确定性表达”的评分机制。这一思路借鉴了标准化测试的设计:对错误答案扣分,对留空题目给予部分分数。研究强调,仅增加不确定性感知测试远远不够,必须彻底重构基于准确率的传统评估框架。否则,模型将继续在“猜测得高分”与“诚实得低分”的矛盾中偏向前者,导致幻觉问题长期存在。
论文同时驳斥了关于幻觉的五大常见误解。例如,有人认为“100%准确率可消除幻觉”,但研究指出现实世界中总存在无法回答的问题;反对者声称“幻觉不可避免”,但实验证明模型可通过“弃权”避免错误;针对“只有大模型会幻觉”的论调,研究发现小模型反而更易识别自身局限——当被问及毛利语问题时,完全不懂的小模型会直接表示“不知道”,而略知一二的模型则需权衡置信度。这些发现表明,幻觉并非神秘缺陷,而是可通过评估机制优化解决的问题。

在技术实践层面,OpenAI透露其最新模型已显著降低幻觉率,并承诺持续优化。与此同时,公司内部正进行组织架构调整:原模型行为团队将向后期训练主管汇报,创始负责人Joanne Jang则转而领导新成立的oai Labs。该团队聚焦于设计人机协作的新界面原型,试图从交互层面减少用户对模型输出的误判风险。这一系列动作显示,行业正从单纯的技术改进转向评估体系与交互设计的系统性革新。