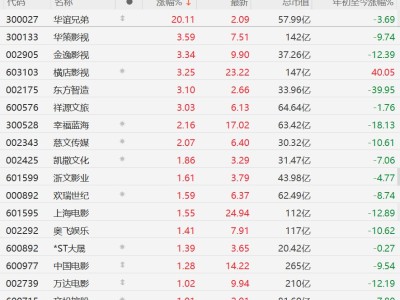
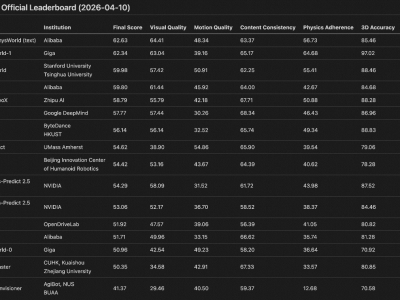
谷歌DeepMind近日宣布对视频生成模型Veo进行重大升级,推出3.1版本并新增多项核心功能。此次更新聚焦于提升AI生成视频的质量与实用性,重点优化了基于参考图片生成视频的能力,同时首次支持原生竖屏视频输出,为短视频创作者提供更专业的工具。
在动态画面生成方面,Veo 3.1展现出显著进步。即使使用简短的文字提示,模型也能生成更自然的角色动作与表情变化,并保持叙事逻辑的连贯性。通过改进的算法架构,系统可精准捕捉参考图中的关键元素,在多镜头切换中维持人物外观、背景细节与物体纹理的高度一致,有效解决传统AI视频生成中常见的"跳帧"或"变形"问题。
针对移动端创作需求,新版模型特别增加了9:16竖屏视频生成功能。这一改进使创作者无需后期裁剪即可直接产出适配手机屏幕的内容,避免因画面压缩导致的画质损失。配合新增的1080p至4K超分辨率输出选项,该技术可同时满足社交媒体日常分享与专业影视制作的不同标准。
技术实现层面,DeepMind团队引入新一代神经网络架构,通过优化注意力机制与时空建模能力,显著提升视频生成的稳定性。在角色一致性测试中,系统能在包含12个场景切换的复杂叙事中,保持主要人物外观特征误差率低于3%。背景元素复用功能则通过建立视觉元素库,实现跨片段的无缝衔接。
目前相关功能已集成至谷歌生态多个产品平台,包括Gemini智能助手、YouTube短视频创作工具、Google Vids专业视频编辑器等。开发者可通过Vertex AI平台调用新版API,企业用户则能在Gemini企业版中获取定制化解决方案。所有生成内容均会自动嵌入SynthID隐形数字水印,配合升级后的内容识别系统,形成完整的AI创作溯源链条。
此次升级标志着AI视频生成技术向专业化、场景化方向迈出重要一步。通过解决画质损耗、角色一致性等核心痛点,Veo 3.1为广告营销、影视预演、教育科普等领域提供了更高效的创作工具。随着原生竖屏支持与多分辨率输出的实现,移动端视频生产流程有望得到进一步简化。