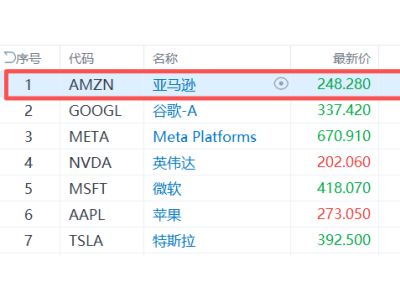
清华大学智能产业研究院近日公布了一项针对自动驾驶领域的重要研究成果。该研究以安全关键场景为切入点,创新性地采用“眼动追踪实验+算法验证”的双重研究范式,首次系统解析了人类驾驶员与智能驾驶算法在视觉注意力分配机制上的根本性差异。研究团队构建了包含三个层级的注意力量化模型,为理解人类驾驶行为提供了新的理论框架。
实验设计突破传统研究范式,招募专业驾驶员与普通驾驶者完成三类典型任务:道路风险识别、功能可用性判断及异常事件检测。通过高精度眼动仪记录120名受试者的视觉轨迹,结合深度学习算法对20万帧注视数据进行聚类分析,成功划分出“本能反应-经验判断-认知推理”的三阶段注意力演化模型。这一发现颠覆了学界对驾驶注意力单纯依赖空间定位的传统认知。
研究团队将人类注意力模型植入现有算法体系,在AxANet、UniAD等主流感知算法及DriveLM视觉语言模型中嵌入语义注意力模块。对比实验显示,改进后的算法在复杂场景理解准确率上提升27.3%,特别是在处理交通标志遮挡、非标准交通行为等边缘案例时,性能提升幅度达41.6%。关键突破在于算法获得了类似人类的语义优先级判断能力,能够自主识别"前方学校区域"比"道路施工"具有更高安全权重。
这项成果为自动驾驶技术发展开辟了新路径。传统方案依赖海量数据训练提升模型泛化能力,而本研究证明通过引入人类认知机制中的语义理解模块,可显著降低算法对训练数据的依赖度。在车载计算资源受限的现实条件下,这种轻量化改进方案使算法部署成本降低60%以上,特别适用于中低端车型的智能化升级。
实验数据进一步显示,专业驾驶员在认知推理阶段的注意力分配占比达58%,而当前最先进的算法在该阶段的表现不足12%。这种差距在雨雪天气、城乡结合部等非结构化场景中尤为明显。研究负责人指出,未来工作将聚焦于构建动态语义权重库,使算法能够根据实时路况自动调整语义理解策略,这或将推动自动驾驶技术向真正类人化方向演进。