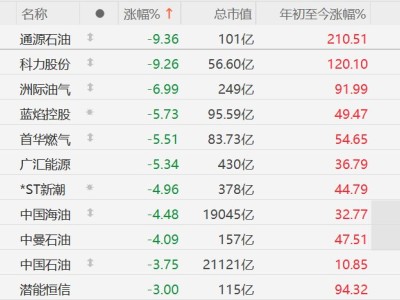
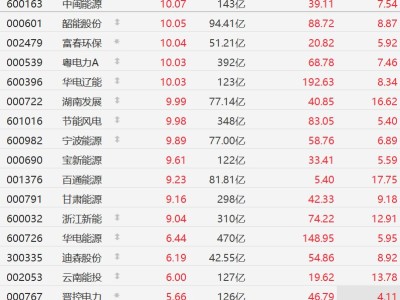
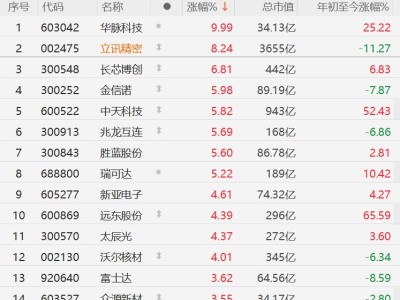
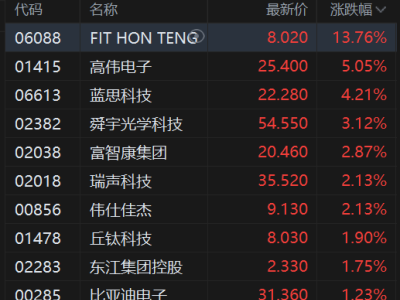
一场关于端侧AI训练的技术革命正在悄然发生。工程师Manjeet Singh与Claude AI团队近日宣布,他们通过逆向工程技术突破了苹果M4芯片神经引擎(ANE)的算力封锁,首次实现了在消费级设备上直接训练Transformer模型的能力。这一成果彻底颠覆了业界对神经网络处理单元(NPU)的认知,标志着个人电脑正式进入大规模AI模型训练时代。
传统观点认为,NPU因架构限制无法承担训练任务,但研究团队通过绕过苹果CoreML框架的层层封装,直接深入MIL编译语言与E5二进制指令集,成功解锁了ANE的完整算力。实验数据显示,M4芯片在运行单层Transformer模型时,峰值能效比达到惊人的6.6TFLOPS/W,这一数值是英伟达A100专业显卡的80倍,较H100更是有50倍以上的优势。更令人震惊的是,整套系统在训练Stories110M模型时,整机功耗控制在1瓦特以内,彻底改写了高性能计算的能耗标准。
这项突破的核心在于硬件操控方式的革新。研究团队开发出全新的底层驱动架构,使ANE能够直接处理梯度计算与参数更新等训练核心环节,而不再局限于传统的推理任务。在Mac mini的实测中,系统不仅完成了模型完整训练流程,其迭代效率甚至接近部分入门级GPU集群。对于独立开发者而言,这意味着过去需要数万美元投入的算力成本,如今只需一台售价数百美元的消费级设备即可实现。
技术社区对此反应热烈。多位AI工程师指出,这项成果将彻底改变小型团队的技术路线选择。当GPU集群的维护成本与数据安全风险成为过去式,家庭实验室与个人开发者将获得前所未有的研发自由度。有开发者形象地比喻:"你书桌上的MacBook不再只是代码运行器,它正在进化成能够自主思考的数字伙伴。"
尽管当前实现仍面临内存带宽限制与多节点协同等工程挑战,但研究团队已开放部分底层代码库。这种开源协作模式正在吸引全球开发者参与优化,有专家预测,随着驱动层的持续改进,M4芯片的算力利用率有望在半年内提升300%。这场由消费电子设备引发的AI训练革命,或许才刚刚拉开序幕。