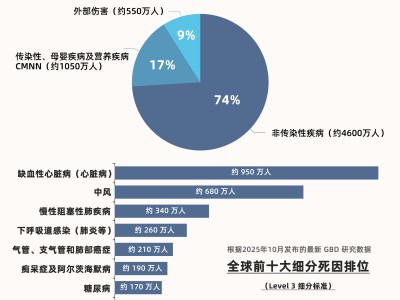
近期,世界模型(WMs)在人工智能领域引发了广泛关注,这一技术不仅挑战了传统视觉语言动作(VLA)模型的地位,更被视为通向物理智能与通用人工智能(AGI)的关键桥梁。本文将深入探讨世界模型的内涵、运作机制及其相较于VLA模型的独特之处。
世界模型,简而言之,是一种能够模拟现实世界动态变化的内部表示系统。与静态感知模型不同,世界模型具备生成与预测能力,可以预见世界随时间的演变,从而允许智能体在行动前进行规划与推理。这一技术前沿的研究机构众多,如meta FAIR、斯坦福World Labs、NVIDIA Cosmos及ZhiCheng AI等,尽管实现路径各异,但均致力于赋予智能体对环境的深刻理解。
世界模型的核心构成包括多模态输入处理、时间预测、潜在特征学习、自我监督学习以及模拟与推理。它们能够整合视频、图像、传感器数据乃至语言信息,形成统一的特征表征,并通过学习历史数据预测未来状态。这一过程不仅涉及对抽象状态空间的操作,还依赖于自我监督学习机制,最终使模型能够模拟多种假设场景,为规划、安全及适应性提供关键支持。
世界模型的应用场景广泛,涵盖了自动驾驶中的路况预测、机器人的操作与移动、合成数据的生成以及具身推理中的物理常识应用。在自动驾驶领域,世界模型能够预测其他车辆与行人的动态,提高行驶安全性;在机器人领域,它们则助力机器人更精准地完成复杂任务;世界模型还能生成高质量的训练数据,加速其他AI模型的研发进程。
与VLA模型相比,世界模型展现出显著的不同。VLA模型,如RT-2或OpenVLA,擅长利用大规模视觉与语言数据理解指令并作出响应,但通常缺乏构建内部世界模型的能力。相比之下,世界模型通过内部模拟进行预测规划,展现出更理想的向前推理与环境适应能力。尽管VLA模型在泛化性方面表现出色,但在物理理解层面则相对浅显。
在具身智能领域,世界模型与其他技术流派并存,各展所长。经典自动化控制基于物理优化,精度高但适应性不足;深度强化学习通过试错学习策略,功能强大但数据效率低下;而遥操与模仿学习则从人类演示中汲取知识,数据需求低但可扩展性受限。多模态传感器融合与空间智能则结合了多种感官信息,提供了丰富的环境感知,但计算成本较高。这些技术并非孤立存在,而是可以相互融合,共同推动智能体的发展。

值得注意的是,世界模型并非完美无缺,但它们为智能物理交互奠定了坚实基础,标志着向嵌入式AGI迈出的重要步伐。通过内化理解、模拟与预测,世界模型为物理AI的持续行动、适应与学习提供了核心动力。随着技术的不断进步,世界模型有望在更多领域展现其独特价值,推动人工智能向更高层次迈进。