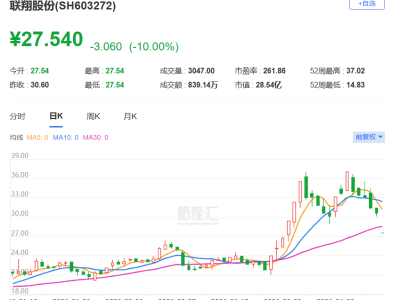
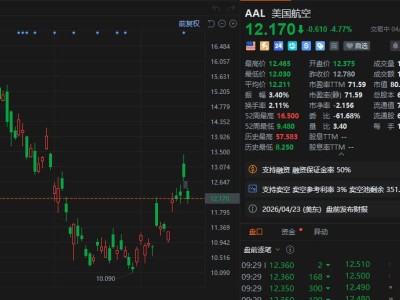
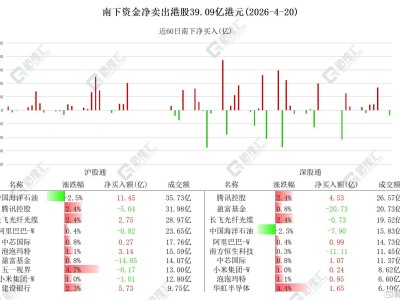
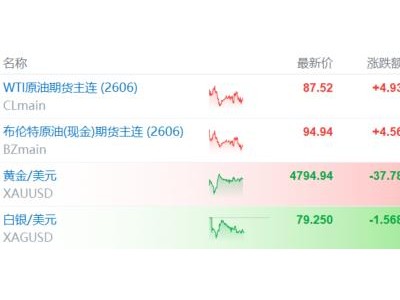
在人工智能领域,一场无声的革命正在悄然发生。meta,这家科技巨头,近期宣布了一项重大突破:他们利用17亿张图片,通过自监督学习(SSL)技术,成功训练出了一个名为DINOv3的“视觉全能模型”。这一成果不仅刷新了计算机视觉的性能天花板,更在医疗、卫星监测、自动驾驶等多个领域引发了轰动。
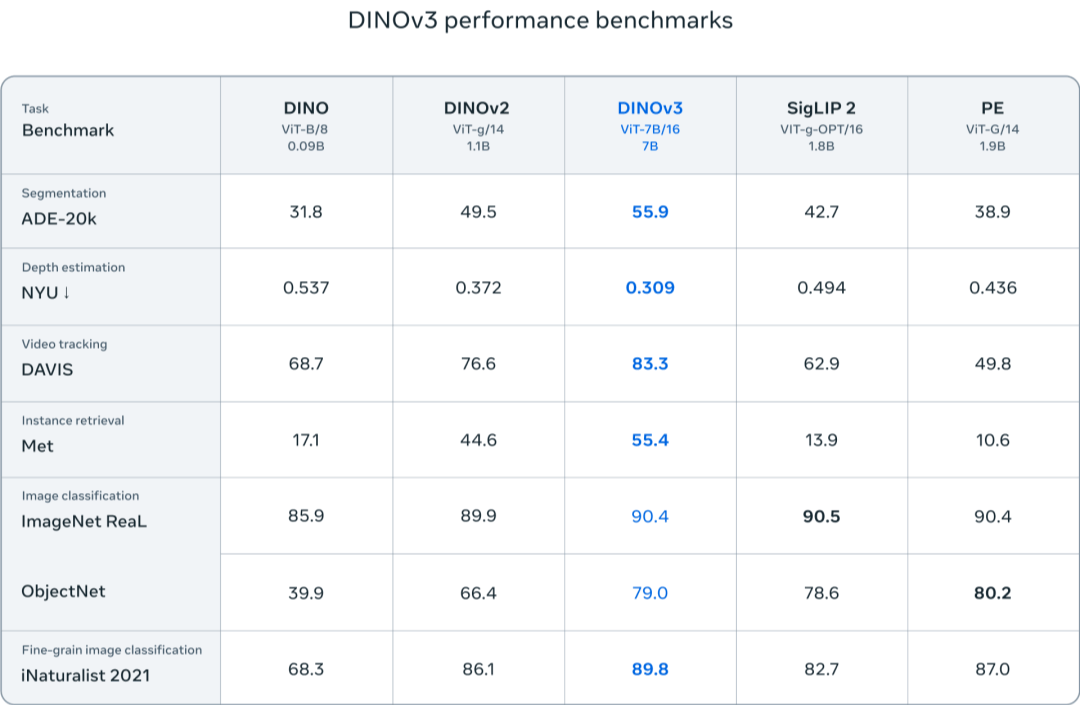
DINOv3,这个拥有70亿参数的“视觉巨兽”,其强大之处在于能够生成高质量、高分辨率的图像特征。在多个密集预测任务中,DINOv3首次超越了专为这些任务设计的解决方案,展现出了前所未有的通用性和高效性。这一突破,标志着自监督学习在计算机视觉领域取得了新的胜利。
更令人瞩目的是,美国的NASA已经将DINOv3应用到了火星探索任务中。这一壮举不仅证明了DINOv3的强大实力,也彰显了meta在AI技术上的领先地位。此前,许多人曾质疑meta在AI竞赛中的地位,但DINOv3的出现无疑为他们正了名。
而且,meta这次是真开源:DINOv3不仅允许商用,还公开了完整的预训练主干网络、适配器、训练与评估代码等“全流程”。这意味着研究者和开发者可以更容易地获取和使用这一先进技术,推动更多创新应用的诞生。
DINOv3的亮点之一是其强大的自监督学习能力。这种技术使得模型能够在没有人工标注数据的情况下进行训练,大大降低了对标注资源的依赖。这对于那些标注稀缺、成本高昂或根本无法获取标注的场景来说,无疑是一个巨大的福音。例如,在卫星影像预训练方面,DINOv3表现出了卓越的性能,为树冠高度估计等下游任务提供了有力支持。
DINOv3还刷新了自监督学习超越弱监督学习的里程碑。在多个基准测试中,DINOv3都取得了当前最优的表现。这意味着,即使在冻结权重条件下,DINOv3也能实现高效的目标检测等任务,无需为特定任务进行微调。
DINOv3的影响已经远远超出了学术界。世界资源研究所(WRI)正在利用这一新技术监测森林砍伐并支持生态修复工作。通过分析卫星影像,WRI能够准确检测受影响生态区域的树木损失和土地利用变化,从而更有效地保护脆弱的生态系统。

DINOv3的成功不仅在于其强大的性能,更在于其广泛的适用性和高效性。meta构建了一个模型家族,包括不同大小的版本,以满足各种研究和开发需求。通过将大型模型蒸馏成更小但性能优越的版本,DINOv3能够在不同计算资源限制下实现高效部署。
随着DINOv3的广泛应用,我们有理由相信,这一新技术将推动更多行业的创新和进步。无论是医疗保健、环境监测还是自动驾驶等领域,DINOv3都将为大规模视觉理解提供更加精准、高效的支持。