DeepSeek在AI领域迈出了重要步伐,其最新发布的V3.1版本不仅在技术层面实现了显著提升,还在软硬件协同方面带来了创新突破。通过引入UE8M0 FP8 Scale参数精度,DeepSeek成功降低了内存使用,最高可减少75%,从而在实际应用中减轻了对进口高端GPU芯片的依赖。
这一进步意味着DeepSeek正携手国产GPU芯片厂商,共同推进算力自主化进程。DeepSeek的这一举措,不仅激发了国内资本市场对科技领域的浓厚兴趣,还预示着中国AI企业在软硬件结合方面将迎来新的发展机遇。
V3.1版本的发布,标志着DeepSeek向Agent时代迈出了坚实的一步。与以往版本不同,V3.1采用了混合推理架构,使模型能够同时支持思考模式和非思考模式。这一转变与GPT-5的“统一系统”理念不谋而合,即通过对话模型、思考模型和实时路由的结合,提升AI系统的整体性能。
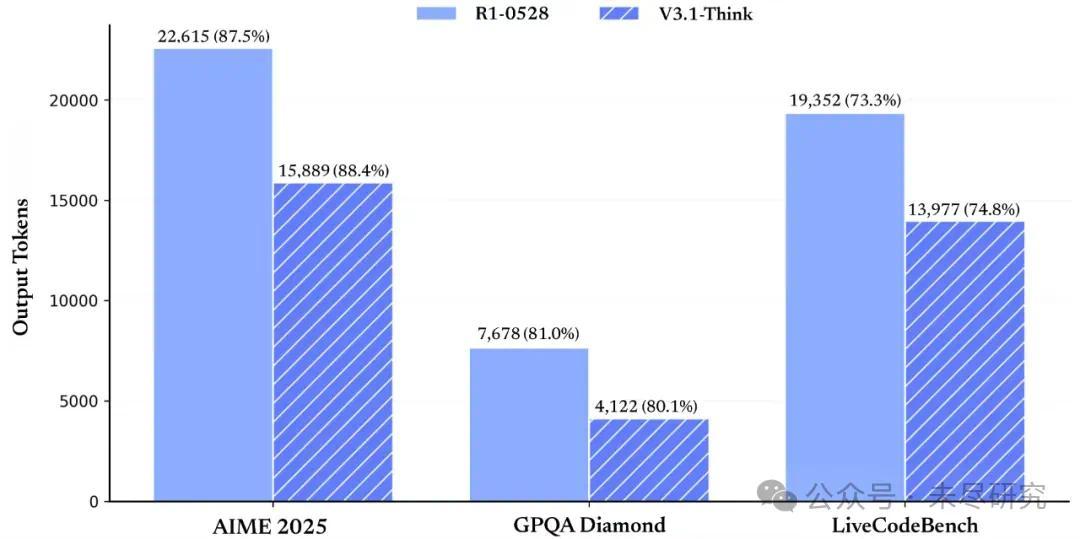
DeepSeek V3.1在思考效率上的提升尤为显著。相比之前版本,V3.1在回答同样问题时,消耗的token更少,所需时间更短。这一改进不仅在经济上具有优势,还提升了用户体验,使回答更加简洁明了。
V3.1在Agent能力上的增强同样引人注目。通过后训练优化,新模型在工具使用和智能体任务中的表现有了显著提升。V3.1的基础模型在V3的基础上进行了外扩训练,增加了840B token的训练量,上下文长度和思考模式均达到了128k,进一步提升了性能。
DeepSeek在中文官微上强调了V3.1使用的UE8M0 FP8 Scale参数精度,而这一信息在其英文账号上并未提及。UE8M0 FP8是一种超低精度表示方式,能够显著减少显存和带宽需求,提升推理和训练效率。通过精心设计缩放,DeepSeek成功避免了数值不稳定的问题。
在Hugginface的模型卡中,DeepSeek透露了更多信息。V3.1使用UE8M0 FP8缩放数据格式进行训练,以确保与微缩放数据格式兼容。这意味着V3.1模型在推理和部署时,可以直接在任何支持MXFP8和UE8M0的硬件上运行,无需额外转换。
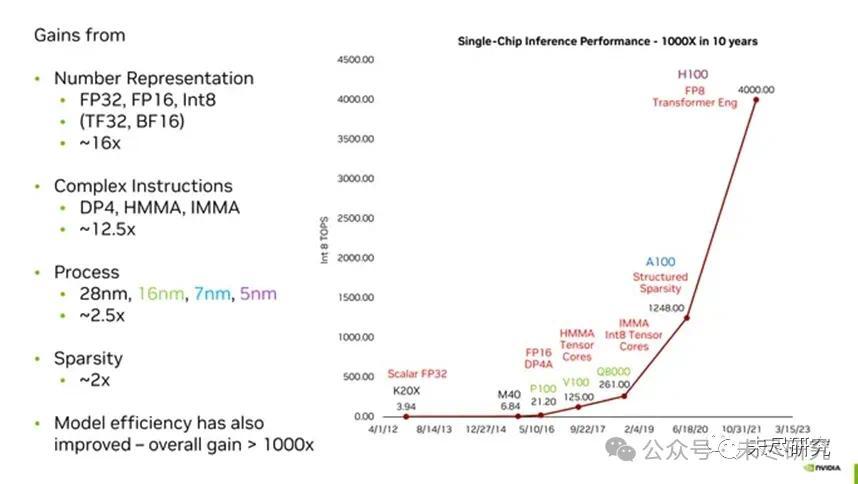
英伟达多年来一直在探索低精度数字表示法以提升推理和训练效率。从FP32到FP16,再到如今的FP8,英伟达不断推出新的数字格式以适应机器学习对算力的需求。DeepSeek此次采用的UE8M0 FP8实际上是一种对数数值系统(LNS)的极简实现,源于加州理工和英伟达的一项联合研究。
DeepSeek的这次升级,不仅使其在中国AI企业的开源热潮中重新夺回领先优势,还展示了其在企业服务能力上向国际前沿AI企业看齐的决心。通过支持strict模式的Function Calling和对Anthropic API格式的支持,DeepSeek进一步提升了其工程可靠性和企业易用性。
对于中国的AI芯片生态而言,DeepSeek的这次升级同样具有里程碑意义。通过与国产GPU芯片厂商的紧密合作,DeepSeek成功推动了超低精度训练在自研芯片上的实现。随着国产芯片和超低精度训练的逐步普及,中国AI产业将迎来更加自主和高效的发展阶段。
英伟达虽然仍保持着在AI芯片领域的领先地位,但DeepSeek等中国企业的崛起正逐渐改变这一格局。通过技术创新和软硬件协同优化,中国AI企业正逐步减少对进口芯片的依赖,走向算力自主化的道路。