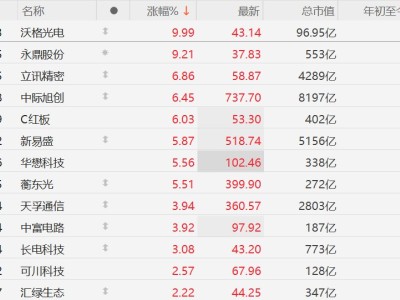
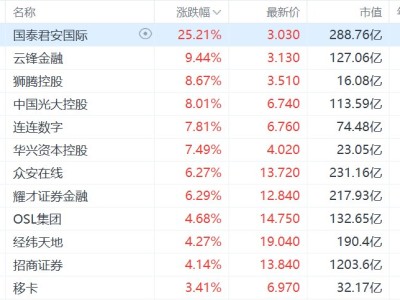
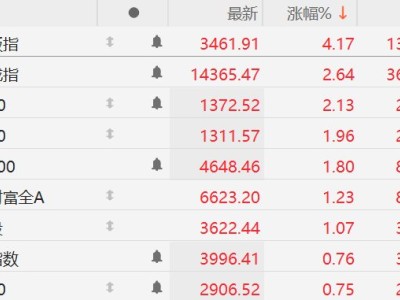
斯坦福大学等多家顶尖机构的研究人员联合开展了一项突破性研究,构建了一个全新的AI能力评测框架——UQ评测体系。该研究已通过学术平台发布,论文编号为arXiv:2508.17580v1,研究团队成员来自斯坦福大学、华盛顿大学、北卡罗来纳大学及Contextual AI等机构。
传统AI评测常被比喻为让考生反复练习历年高考真题,尽管能检验基础能力,但模型很快就能在固定题型中取得高分,形成“应试化”发展。更关键的是,这类测试题往往脱离实际应用场景,难以反映模型解决真实问题的潜力。研究团队提出创新思路:为何不让AI直接挑战人类尚未攻克的难题?这如同要求围棋AI破解千年未解的残局,或数学AI证明悬而未决的猜想。
新评测体系的核心优势在于其双重特性:问题难度足够高,确保不会短期内被AI突破;问题均源自现实需求,解决后能产生实际价值。该体系由三个关键模块构成:包含500个真实未解问题的数据集、基于AI的初步验证系统,以及开放的人类专家验证平台。
数据集构建过程堪称知识考古。研究人员从Stack Exchange网络(涵盖80余个专业领域的问答社区)的300万个未答问题中筛选。初筛阶段通过规则过滤,保留至少两年历史、获得足够关注且无任何解答的问题,将候选范围缩小至3.4万个。第二阶段采用双AI协作模式,一个模型生成答案,另一个评估答案质量,进一步筛选出7685个问题。最终由博士级专家人工审核,结合AI模型的尝试性解答,确定500个高质量难题,其中25个“钻石级”问题因获得超高关注度(浏览量超2000次、赞同票超75个)被特别标注。
问题领域分布广泛,数学与数学物理占据主导,包含专业数学家都难以证明的命题;理论计算机科学贡献了算法复杂性问题;甚至出现科幻爱好者寻找特定书籍、历史学家考证历史细节等跨界难题。这种多样性确保了评测的全面性。
在答案验证环节,研究团队发现AI更擅长评估而非生成答案,据此开发了多层次验证系统。底层检验包含正确性核查、事实逻辑检查和循环一致性验证;中层采用重复采样和迭代反思机制;高层整合多数投票、一致投票和流水线验证策略。实验表明,三阶段流水线验证使准确率从30%提升至80%,但召回率有所下降。系统还发现,同源AI模型在评估时存在“自恋”倾向,复合验证策略有效缓解了这种偏见。
尽管AI验证器表现突出,但其局限性依然明显:最佳系统精确度仅40%,意味着60%的通过答案可能错误;不同验证器的排名结果差异显著,提示不能完全依赖自动化评估。因此,研究团队构建了开放验证平台,邀请全球专家参与最终评判。
该平台设计强调透明与协作,每个问题页面展示详细内容、AI答案、验证结果及推理过程。模型开发者需提交完整提示词以确保可复现性,人类评审者则进行专业打分并提供评判依据。平台支持额外AI评审提交,实时统计解决进度、验证通过率等数据,并建立基于解决问题数量的排行榜。为激励参与,平台提供公开署名、教育价值等回报,原问题提出者也可直接参与验证。
在实战测试中,OpenAI的o3-PRO、Google的Gemini 2.5 Pro、Anthropic的Claude等顶尖模型接受挑战。o3-PRO在500个问题中仅有75个答案通过AI验证(通过率15%),经人类专家确认后,仅10个答案完全正确,其中6个来自数学领域。早期测试中,几乎所有模型都未能产生有效解答,o3-PRO的4个正确解答成为重要突破。失败案例显示,AI常出现引用虚构文献和逻辑细微错误等问题。在25个“钻石级”问题中,虽4个答案通过AI验证,但均未通过人类专家确认。
研究引发了对AI发展方向的深入思考。传统评测如同练习册习题,难以评估解决复杂问题的能力;新方法则像真实科研项目,更能检验创新思维。AI验证强于生成能力的发现,提示“评委型AI”可能比“创作型AI”更具应用前景。动态更新机制确保评测始终处于技术前沿,而社区驱动模式则推动了科学研究的民主化。
对于公众参与,UQ平台已完全开放。访问者可在uq.stanford.edu查看问题和AI答案,具备专业知识者可注册成为验证者,依据平台提供的评判标准和推理过程进行评估。这种开放模式不仅提高了验证质量,也让更多人参与到前沿科学讨论中。