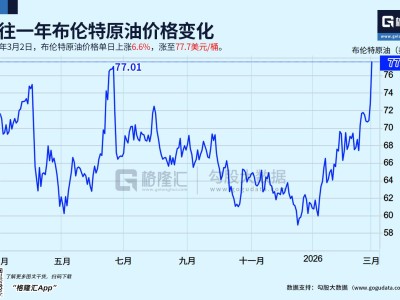
谷歌FACTS团队与数据科学平台Kagle近日联合推出一套名为FACTS的AI模型评估基准工具,旨在解决当前行业对生成式人工智能事实准确性缺乏统一衡量标准的问题。该框架特别针对法律、金融、医疗等对信息可靠性要求严苛的领域设计,通过多维度测试为模型性能提供量化参考。
评估体系将"事实性"拆解为两大核心维度:其一为上下文事实性,要求模型严格基于给定信息生成回答;其二为世界知识事实性,考察模型调用预存知识或网络检索的能力。初步测试显示,包括Gemini3Pro、GPT-5及Claude4.5Opus在内的主流模型,综合准确率均未突破70%门槛,暴露出当前技术存在的系统性缺陷。
不同于传统问答测试,FACTS基准包含四项创新测试模块:参数基准检验模型内部知识储备,搜索基准评估工具调用能力,多模态基准测试视觉信息处理,上下文基准验证逻辑连贯性。为防止数据污染,测试集采用3513个公开样本与保密数据组合的形式,其中Kagle保留的私有数据占比达30%。
在具体测试中,Gemini3Pro以68.8%的综合得分领跑群雄,其搜索模块表现尤为亮眼,获得83.8%的超高评分。但该模型在参数测试中仅取得76.4%的成绩,暴露出知识储备与检索能力的失衡。OpenAI的GPT-5以61.8%位列第三,其整体表现与第二名Gemini2.5Pro(62.1%)差距微小。
多模态测试成为所有模型的共同短板,即便是表现最佳的Gemini2.5Pro,在该模块也仅获得46.9%的准确率。测试数据显示,当前AI系统在处理无监督视觉信息提取时,仍存在显著的精度缺陷,这提示企业在部署相关应用时需建立人工复核机制。
核心发现显示:主流模型事实核查能力普遍不足70%;搜索增强型架构可显著提升回答准确性;多模态处理技术尚未达到商用标准。这些结论为AI研发者提供了明确优化方向,特别是知识检索增强生成(RAG)系统的开发,需重点强化模型与向量数据库的协同能力。