阿里通义近日宣布,其Qwen3-TTS家族迎来重要更新,正式推出两款创新模型——音色创造模型Qwen3-TTS-VD-Flash和音色克隆模型Qwen3-TTS-VC-Flash。这两款模型在语音合成领域展现出卓越性能,为用户带来前所未有的个性化语音体验。
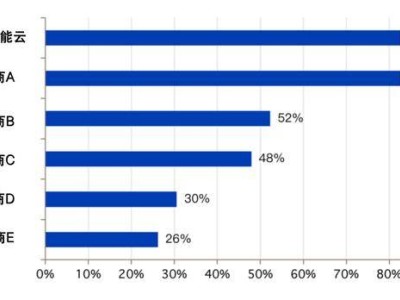
Qwen3-TTS-VD-Flash作为音色创造领域的突破性成果,支持通过复杂自然语言指令实现音色的精细化调控。用户可自由定义音色、韵律、情感及人设等参数,彻底摆脱传统语音合成中预设音色或简单克隆的限制。该模型在InstructTTS-eval评测中表现优异,综合评分显著超越GPT-4o-mini-tts和Mimo-audio-7b-instruct,在角色扮演场景测试中更力压Gemini-2.5-pro-preview-tts。其独特的文本解析能力可自动处理复杂结构,精准提取关键信息,即使面对非规范化文本也能保持稳定输出。
另一款明星模型Qwen3-TTS-VC-Flash则专注于音色克隆技术,仅需3秒音频样本即可完成高精度克隆。该模型支持中、英、德、意、葡、西、日、韩、法、俄等10种主流语言的语音生成,在MiniMax TTS多语种测试集中,其平均词错误率(WER)指标全面领先MiniMax、ElevenLabs及GPT-4o-Audio-Preview等同类产品。特别在中文、英文、法文等语项的内容稳定性测试中,该模型展现出显著优势。
两款模型均具备高度拟人化的语音表现力,能够根据文本语义自动调节语气节奏,输出自然生动的语音内容。在技术实现上,Qwen3-TTS-VD-Flash允许用户通过声学属性、人设描述、背景信息等自由组合,创造独一无二的定制化声音形象;Qwen3-TTS-VC-Flash则通过强化学习算法,在保持克隆音色特征的同时,显著提升多语种语音生成的准确性。
为方便开发者接入,阿里通义同步开放了Qwen3-TTS-Voice-Design和Qwen3-TTS-Voice-Clone的API文档。这两款模型的推出,标志着语音合成技术从"标准化输出"向"个性化创造"的重要跨越,将为有声内容创作、智能客服、虚拟主播等领域带来全新可能。