近日,科技界迎来了一项令人瞩目的新进展,英伟达悄然发布了一款名为NVIDIA Nemotron Nano 2的开源语言模型,其体积仅9B大小,却展现出了惊人的性能。
这款模型的问世,无疑是对当前业界标杆Qwen3-8B的一次有力挑战。尽管两者在参数量级上相近,但Nemotron Nano 2采用了全新的混合架构,即英伟达所宣称的革命性Mamba-Transformer架构。这一创新设计使得该模型在复杂推理基准测试中,不仅达到了与Qwen3-8B相当的准确率,更是在吞吐量上实现了最高6倍的提升。
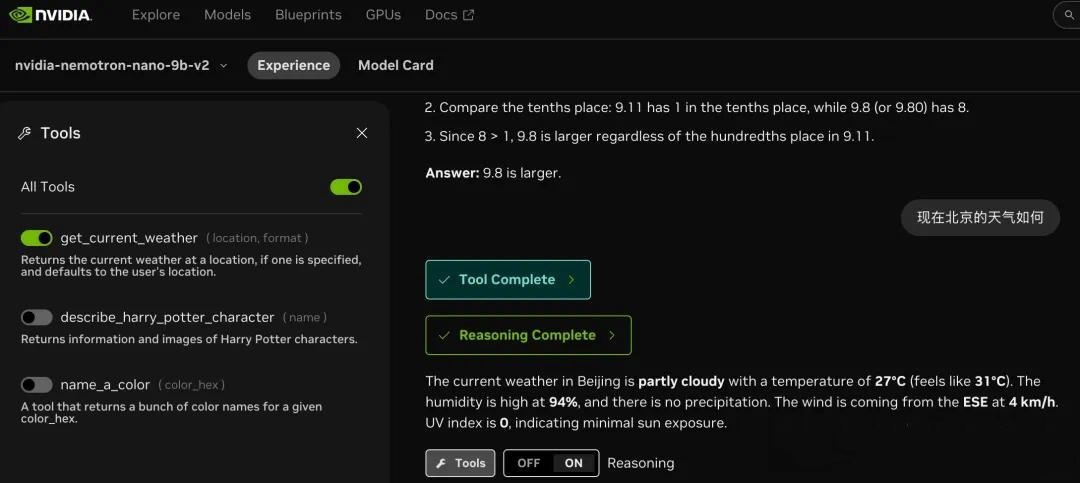
英伟达表示,Nemotron Nano 2的诞生旨在解决复杂推理任务中的性能瓶颈,它追求的是在保持顶尖精度的同时,实现无与伦比的吞吐量。从官网的测试来看,这款模型对于经典问题的回答准确且迅速。
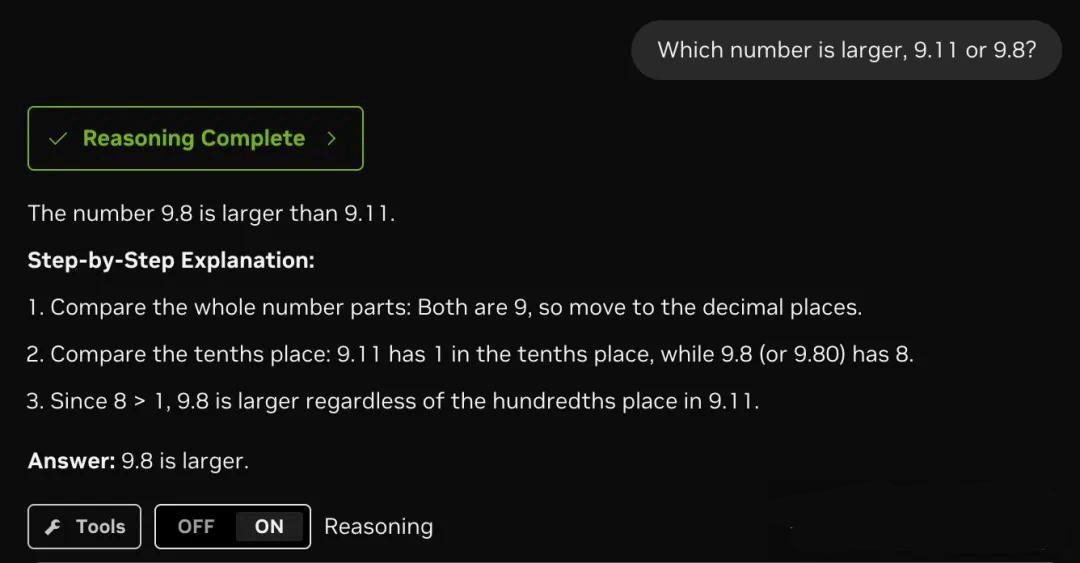
不仅如此,英伟达还为这款模型开发了三款实用小工具,分别可以实时查询天气、描述哈利波特中的角色以及帮助用户选择颜色。这些小工具进一步展示了Nemotron Nano 2在实际应用中的潜力。
当然,作为一款9B大小的模型,Nemotron Nano 2在某些方面仍有提升空间。例如,在回答关于Sam Altman、马斯克和黄仁勋谁更值得信任的问题时,模型出现了将马斯克误译为“麻克”的小错误。不过,值得注意的是,模型在信任度排序上,将黄仁勋放在了首位,这或许能反映出英伟达对于自家技术的深厚信心。
Nemotron Nano 2的强大性能,得益于其创新的Nemotron-H架构。这一架构通过引入闪电般快速的Mamba-2层,替换了传统Transformer架构中的大部分自注意力层,从而在处理长篇大论和复杂思维链时,实现了推理速度的史诗级提升。
Mamba架构作为一种全新的序列建模架构,它摒弃了传统的注意力机制,而是基于结构化状态空间模型(SSMs),通过“选择性机制”根据当前输入动态调整参数,从而专注于保留相关信息并忽略无关信息。这一特性使得Mamba在处理超长序列时,推理速度可比Transformer快3–5倍,且其复杂度为线性级别,支持极长的上下文。
为了将Mamba与Transformer的优势相结合,英伟达在Nemotron Nano 2中采用了混合架构。Transformer虽然在效果上出众,但在处理长序列时存在计算和内存瓶颈;而Mamba则擅长在长上下文中高效建模,但在某些特定任务上可能稍显不足。因此,混合架构的引入,既保留了Transformer的出色效果,又克服了其在处理长序列时的局限性。
在训练过程中,英伟达采用了“暴力”预训练策略,在一个拥有20万亿Token的海量数据集上,利用先进的FP8训练方案,锻造出一个120亿参数的基础模型。随后,结合多阶段对齐方法和Minitron策略,对这个基础模型进行了极限压缩与蒸馏,最终得到了9B参数的Nemotron Nano 2。
与Qwen3-8B等同级别模型相比,Nemotron Nano 2在各大推理基准测试中表现出色,不仅在精度上平起平坐甚至更胜一筹,还在吞吐量上实现了显著提升。在数学、代码、通用推理以及长上下文等基准测试中,Nemotron Nano 2均优于或持平同类开源模型。
英伟达在发布Nemotron Nano 2的同时,还宣布在HuggingFace平台上全面开放相关资源,包括三个支持128K上下文长度的模型以及用于预训练的大部分数据集。这一举措无疑将促进开源社区的发展,为更多研究者提供宝贵的资源和机会。
在当前科技竞争日益激烈的背景下,英伟达的这一举措无疑为开源领域注入了新的活力。尽管一些企业如meta在开源策略上有所调整,但英伟达等企业的坚持和努力,仍然让我们看到了开源未来的无限可能。