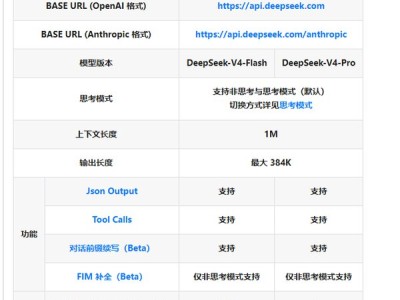
字节跳动旗下的Seed团队近日宣布了一项重大开源举措,正式推出了Seed-OSS系列模型。这一系列模型专为处理长上下文、推理任务、Agent行为及通用场景设计,其上下文窗口扩展至前所未有的512k,这一数字是业界常规上下文窗口(128k)的四倍,甚至超越了GPT-5的两倍,相当于能够一次性处理约1600页文本的内容。
Seed-OSS系列模型特别针对推理任务进行了优化,并赋予用户调节思维预算的灵活性,以满足不同应用场景的需求。此次开源包含了三个版本:基础模型Seed-OSS-36B-Base、无合成数据基础模型Seed-OSS-36B-Base-woSyn,以及经过指令微调的Seed-OSS-36B-Instruct。
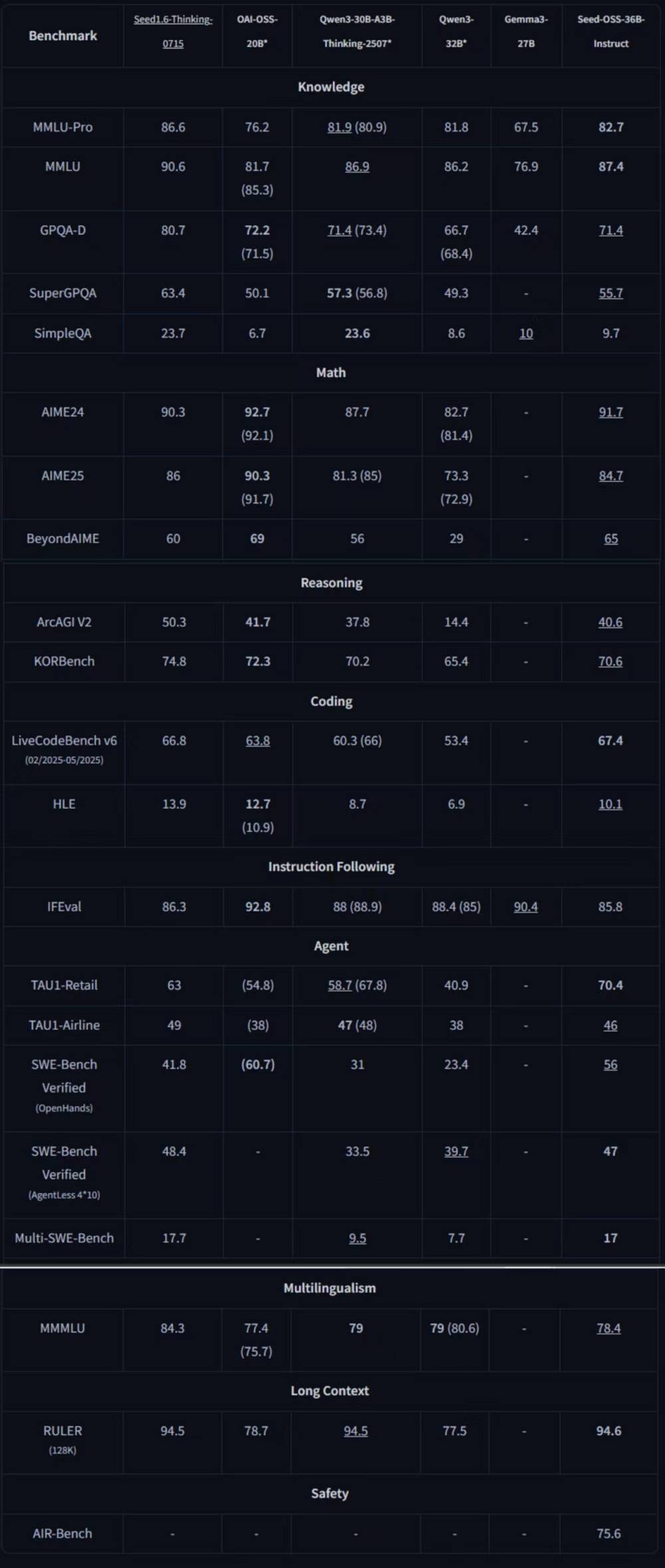
在多个基准测试中,经过指令微调的Seed-OSS-36B-Instruct展现了出色的性能,在通用知识、Agent行为、编程及长上下文等领域取得了7项开源模型中的最佳表现(SOTA)。其整体能力超越了Qwen3-32B、Gemma3-27B及gpt-oss-20B等模型,与Qwen3-30B-A3B-Thinking-2507在多数领域不相伯仲。
Seed-OSS系列模型遵循宽松的Apache2.0开源协议,并计划在未来发布详细的技术报告。这些模型采用了12万亿个token的预训练数据,基于当前主流的因果语言模型架构,即预测下一个token的模型类型,且全部为稠密模型,未采用MoE等复杂架构。
在技术创新方面,Seed-OSS系列结合了多项关键技术,包括RoPE(旋转位置编码)、GQA注意力机制、RMSNorm归一化及SwiGLU激活函数等,这些组件的组合旨在提升训练稳定性和推理性能。尤为Seed-OSS的512k上下文窗口并非后续扩展,而是原生训练的结果。
模型还引入了思考预算功能,帮助开发者控制推理成本并优化使用体验。根据Seed团队的分享,对于简单任务,随着思维预算的增加,模型分数波动不大;而对于复杂任务,分数则会随着思维预算的增加而提升。在默认模式下,模型没有思考长度限制,但若指定思维预算,建议优先考虑512的整数倍值。
Seed-OSS系列模型一经发布,便获得了开发者社区的广泛认可。Hugging Face的工程师Tiezhen Wang评价称,这一系列模型非常适合进行消融研究,能够以较低成本探索不同组件对大模型性能的影响。社区成员也纷纷表示,如此规模的基础模型在开源界较为罕见,且长上下文能力对实际应用具有重要意义。
近期,字节跳动Seed团队频繁开源多款模型,除了Seed-OSS系列外,还包括多语言翻译模型Seed-X、智能体模型Tar系列及图像编辑模型Vincie等。这一系列举措表明,开源正逐渐成为模型发布的重要选择,甚至像OpenAI这样原本坚持闭源的厂商也开始逐步开源其模型。字节跳动此次将核心语言模型贡献给社区,无疑为开源研究提供了更多基础模型的选择。